Search
Items tagged with: passwordHashing
Ever since the famous “Open Sesame” line from One Thousand and One Nights, humanity was doomed to suffer from the scourge of passwords.
Even in a world where we use hardware tokens with asymmetric cryptography to obviate the need for passwords in modern authentication protocols, we’ll still need to include “something you know” for legal and political reasons.
In the United States, we have the Fifth Amendment to the US Constitution, which prevents anyone from being forced to testify against oneself. This sometimes includes revealing a password, so it is imperative that passwords remain a necessary component of some encryption technologies to prevent prosecutors from side-stepping one’s Fifth Amendment rights. (Other countries have different laws about passwords. I’m not a lawyer.)
If you’ve ever read anything from the EFF, you’re probably keenly aware of this, but the US government loves to side-step citizens’ privacy rights in a court of law. They do this not out of direct malice towards civil rights (generally), but rather because it makes their job easier. Incentives rule everything around me.
Thus, even in a passwordless future, anyone who truly cares about civil liberties will not want to dispense with them entirely. Furthermore, we’ll want these password-based technologies to pass the Mud Puddle test, so that we aren’t relying on large tech companies to protect us from government backdoors.
Given all this, most security professionals will agree that passwords suck. Not only are humans bad sources of randomness, but we’re awful at memorizing a sequence of characters or words for every application, website, or operating system that demands a password.
None of what I’ve written so far is the least bit novel or interesting. But here’s a spicy take:
The only thing that sucks worse than passwords is the messaging around password-based cryptographic functions.
Password-Based Cryptographic Functions
That isn’t a term of the art, by the way. I’m kind of coining it as a superset that includes both Password-Based Key Derivation Functions and Password Hashing Functions.
You might be wondering, “Aren’t those two the same thing?” No, they are not. I will explain in a moment.
The intersection of human-memorable secrets (passwords) and cryptographic protocols manifests in a lot of needless complexity and edge-cases that, in order to sufficiently explain anything conversationally, will require me to sound either drunk or like a blue deck player in Magic: The Gathering.

Art: CMYKat
To that end, what I’m calling Password-Based Cryptographic Functions (PBCFs) includes all of the following:
- Password-Hashing Functions
- Bcrypt
- Password-Based Key Derivation Functions
- Scrypt
- Argon2
- PBKDF2
- bscrypt
- Balanced Password Authenticated Key Exchanges
- CPace
- Augmented Password Authenticated Key Exchanges
- SRP
- AuCPace
- BS-SPEKE
- Doubly-Augmented Password Authenticated Key Exchanges
- OPAQUE
- Double BS-SPEKE
If you tried to approach categorization starting with simply “Key Derivation Functions”, you’d quickly run into a problem: What about HKDF? Or any of the NIST SP 800-108 KDFs for that matter?
If you tighten it to “Password-Based KDFs” or “Key-stretching functions”, that doesn’t include bcrypt. Bcrypt is a password hashing function, but it’s not suitable for deriving secret keys. I’ve discussed these nuances previously.
And then you have some password KDF and/or hashing algorithms that are memory-hard, some that are cache-hard.
And then some Password Authenticated Key Exchanges (PAKEs) are quantum-annoying, while others are not.

To make heads or tails of the different algorithms, their properties, and when and where you should use them, you’d either need to secure postdoc funding for cryptography research or spend a lot of time reading and watching passwords-focused conference talks.

(Selfie taken by Sc00bz (left) at DEFCON 30 in the Quantum Village.)
So let’s talk about these different algorithms, why they exist to begin with, and some of their technical details.

Why Does Any of This Matter?
The intersection of passwords and cryptography is one of the foundations of modern society, and one that most Internet users experience everywhere they go.
You’ll know you have succeeded in designing a cryptographic algorithm when the best way to attack it is to try every possible key. This is called an exhaustive search, or a brute-force attack, depending on the disposition of the author.
Remember earlier when I said passwords suck because humans are bad at creating or remembering strong, unique passwords for every website they visit?
Well, it turns out, that some passwords are extremely common. And even worse, people who choose common passwords tend to reuse them everywhere.
This presented a challenge to early web applications: In order to have authenticated users, you need to collect a password from the user and check it on subsequent visits. If you ever get hacked, then it’s likely that all of your users will be impacted on other websites they used the same passwords for.
Including their bank accounts.
So the challenge for any password-based scheme is simply stated: How can you safely authenticate users based on a secret they know?
Enter: Hashing
Storing a hash of a password is an obvious solution to this predicament. Early solutions involved using the user’s password as an encryption key, rather than building atop cryptographic hash functions.
However, it’s important not to call it “password encryption”.
The reason isn’t merely pedantic; it’s meant to prevent a disaster from repeating: Adobe famously encrypted passwords with Triple-DES instead of hashing them.
In early UNIX-based operating systems, your password hashes were stored in a file called /etc/passwd, along with other user account data. These days, your actual password hashes are kept in a second file, /etc/shadow, which is only readable by root.
Unfortunately, the tool used to create password hashes was called crypt, so the “encryption” lingo stuck.
When Hashing Isn’t Enough
Although encrypting passwords is bad, using a fast cryptographic hash function (e.g. SHA256 or BLAKE2) is also bad.
LinkedIn learned this lesson the hard way in 2012, when an attacker leaked 117 million users’ hashed passwords. It turns out, they used SHA1 as their password hashing function.
Hash functions are deterministic: If you feed them the same input, you will always get the same output.
When your password hashing strategy is simply “just use SHA1”, two users with the same password will have an identical password hash.
People are bad at creating, or remembering, unpredictable passwords.
When you combine these observations, there are some extremely obvious candidates (123456, password, etc.) to prioritize when guessing.
Additionally, you could precompute these hashes once and build a reverse index of the passwords that hash to a specific output. This is called a rainbow table.
Unlike most of symmetric cryptography, where the goal ends at forcing the attacker to perform an exhaustive brute-force search of every possible key, password-based cryptography has to go the extra mile to prevent weak secrets from being compromised; a very tall order for anyone to contend with.
Towards Modern Password Hashing
None of this was a surprise to security experts in 2012. There were a couple generally known best practices since I first learned programming in the 2000s:
- Salt your passwords (to mitigate rainbow tables)
- Use an iterated hashing scheme, rather than a fast hash (to make each step of an exhaustive search slower)
PBKDF2, the first widely used password hashing and key derivation function, did exactly that:
- PBKDF2 was designed to support randomly-generated per-user salts.
- It used HMAC in a loop to force attackers to spend extra CPU cycles per guess. If an attacker could guess 10 million passwords per second against SHA-256, then using 100,000 iterations of PBKDF2 slowed them down to less than 100 guesses per second (due to HMAC calling the hash function twice).
And that might sound like the end of the story (“PBKDF2 wins”), but the password cracking community is extremely clever, so it’s only just begun.
Parallel Attacks and GPUs
Since your CPU can only guess a few hashes per second, PBKDF2 is a thorny problem to contend with.
However, there’s an easy way for attackers to use commodity hardware to bypass this limitation: Graphics cards are specially designed to perform a lot of low-memory calculations in parallel.
If you can write your password cracking code to leverage the benefits of GPUs instead of CPUs, then PBKDF2 becomes easy potatoes.
The other secure password hashing algorithm in use at the time, bcrypt, had only a linear improvement over PBKDF2’s security against GPU attacks.
Memory-Hard Password Hashing Algorithms
In 2009, Colin Percival proposed scrypt to mitigate this risk. Scrypt (pronounced “ess crypt”) builds atop PBKDF2-SHA256 by hashing psuedorandom regions of memory with Salsa20/8 (hence the S in Scrypt) in a way that makes it difficult to precompute.
Scrypt hashes require large amounts of memory to compute (at least 16 megabytes, in the recommended minimum configuration, versus the few kilobytes of incumbent password hashes).
While GPUs (and FPGAs, and ASICs, and …) are great for cracking password hashes that use CPU-bounded algorithms, algorithms that access large amounts of memory are difficult to attack effectively.
It’s still possible for clever programmers to work around this memory/bandwidth limitation, but to do so, you must compute more operations, which makes it not worthwhile.
Cryptographers and the password-cracking community call this expensive time-memory trade-off memory hardness. In 2016, it was determined that scrypt is maximally memory-hard.
Password Hashing Competition
The Password Hashing Competition (PHC) was kicked off by JP Aumasson in 2012 to develop a new standard for password hashing and password-based key derivation.
In 2015, they selected Argon2 as its recommendation, with four finalists receiving special recognition (Catena, Lyra2, Makwa, and yescrypt–which is based on scrypt).
Cache-Hardness
In the years since the PHC concluded, the advances in password cracking techniques have not slowed down.
One of the PHC judges recently proposed a new algorithm called bscrypt which purports a property called “cache hard” rather than “memory hard”. The reasoning is that, for shorter run times, memory bandwidth and small CPU caches is a tighter bottleneck than overall memory requirements.
In fact, there’s an Argon2 variant (Argon2ds) which offers cache-hardness.
Two Hard Choices
So which of the two should you care about, as a defender?
If you’re validating password hashes in an online service, a cache-hard algorithm might make more sense. You’re incentivized to have shorter server-side run times to avoid DoS attacks, so the benefits of cache-hardness seem more impactful than memory-hardness.
If you’re deriving a sensitive cryptography key from a password and can afford to take several seconds of wall-clock time, a memory-hard algorithm is likely to be a better fit for your threat model.
(Or, like, run both a cache-hard and memory-hard algorithm and use a fast KDF, such as HKDF, to mix the two into your final cryptography key.)
Of course, the story doesn’t end here. Password Hashing and Password-Based Key Derivation continues to mature as the password cracking community discovers new attacks and engineers defenses against them.

A Strange Game; The Only Winning Move is to PAKE
Password hashing is a defense-in-depth against a system compromise that enables attackers to perform offline attacks against a cryptographic output to determine a user’s password.
However, for many applications, the bigger question is, “Why even play this game in the first place?”
Password-Authenticated Key Exchanges
A password authenticated key exchange (PAKE) algorithm is an interactive protocol to establish keys based on at least one party’s knowledge of a password.
PAKEs are what enable you to log into encrypted WiFi connections and encrypt your traffic. PAKEs prevent you from having to reveal the password (or a password-equivalent value, such as a password hash) to the other party.
Although there are a lot of proposed PAKE algorithms, the one that most people implemented was SRP (“Secure Remote Password”), which was intuitively a lot like Diffie-Hellman but also not Diffie-Hellman (since SRP used addition).
For a good teardown on SRP, Matthew Green’s blog is highly recommended.
There are a few real-world cryptography problems with using SRP:
- You need to use a special kind of prime number for your protocol. The standard Diffie-Hellman moduli are not suitable for SRP; you want a safe prime (i.e. a number of the form N = 2q + 1, where q is also prime).
- One of the steps in SRP, client-side, is to compute
A = g^a (mod N). Here,Ais a public value whileais a secret (usually the SHA1 hash of the username and pasword).
If your software implementation of modular exponentiation (a^x mod P) isn’t constant-time, you leaka, which is a password-equivalent value.
Additionally, it’s not possible to use SRP with elliptic curve groups. (Matthew Green’s post I linked above covers this in detail!)
Thus, SRP is generally considered to be deprecated by security experts, in favor of other PAKEs.
IETF, CFRG, PAKE Selection
As early as IETF 104, the Crypto Forum Research Group (CFRG) began exploring different PAKE algorithms to select for standardization.
One of the motivators for this work is that the WiFi alliance had shoehorned a new PAKE called Dragonfly into their WPA3, which turned out to be badly designed.
The CFRG’s candidate algorithms and reviews were publicly tracked on GitHub, if you’re curious.
TL;DR – They settled on recommending OPAQUE as an augmented PAKE and CPace as a balanced PAKE.
Sc00bz has done multiple talks at security conferences over the years to talk about PAKEs:
https://www.youtube.com/watch?v=28SM5ILpHEE
Quantum Annoyance
The PAKEs we’ve discussed involved a cyclic group (and the newer ones involved an elliptic curve group). The security of these schemes is dependent on the hardness of a discrete logarithm problem.
If a cryptography relevant quantum computer (CRQC) is developed, discrete logarithm problems will cease to be hard.
Some PAKEs fall apart the moment a discrete log is solvable. This is par for the course for Diffie-Hellman and elliptic curve cryptography.
Others require an attacker to solve a discrete log for every guess in an offline attack (after capturing a successful exchange). This makes them annoying for quantum attackers.
While they don’t provide absolute security like post-quantum cryptography, they do make attackers armed with a CRQC work harder.
OPAQUE isn’t quantum annoying. Simply observe all of the packets from making an online guess, solve the DLP offline, and you’re back to the realm of classical offline guessing.

The State of the Art
At this point, you may feel somewhat overwhelmed by all of this information. It’s very tempting to simplify all of this historical context and technical detail.
You might be telling yourself, “Okay, Scrypt, Argon2, CPace, OPAQUE. Got it. That’s all I need to remember. Everything else is questionable at best. Ask a cryptographer. I’m bailing out, yo!”
But the story gets worse on two fronts: Real-world operational requirements, and compliance.
Your Hands Are Tied, Now Swim
If you’re selling a product or service to the US government that uses cryptography, you need to first clear a bare minimum bar called FIPS 140.
FIPS 140 is opinionated about which algorithms you use. For password hashing and password-based key derivation, FIPS defers to NIST SP 800-209, which means you’re only permitted to use PBKDF2 in any FIPS modules (with a SHA2- family hash function). (Update: See below.)
So all of the information about memory-hard and cache-hard password hashing algorithms? This is useless for you if you ever try to sell to the US government.
An open question is whether Scrypt is FIPSable due to it building atop PBKDF2. To be blunt: I’m not sure. Ask a NIST Cryptographic Module Validation Program lab for their opinion.
Update (2022-01-07): A Brief Correction
Thanks to FreakLegion for pointing this out.
According to NIST SP 800-63B, memory-hard hash functions are recommended.
Examples of suitable key derivation functions include Password-based Key Derivation Function 2 (PBKDF2) [SP 800-132] and Balloon [BALLOON]. A memory-hard function SHOULD be used because it increases the cost of an attack.NIST SP 800-63B
Don’t use Balloon, though. It’s under-specified.
FreakLegion indicates in their Hacker News comment that scrypt and yescrypt are both acceptable.
End Update
In the realm of PAKEs, both CPace and OPAQUE are frameworks that can be used with multiple elliptic curve groups.
Both frameworks support NIST P-256, but CPace supports X25519 and OPAQUE supports Ristretto255; these are currently not FIPSable curves.
“I don’t care about FIPS. Argon2 all the things!”
JavaScript runtimes don’t provide a built-in Argon2 implementation. This poses several challenges.
- Do you care about iOS users? Lockdown mode prevents you from using WebAssembly, even in a browser extension.
- Trying to polyfill scrypt or Argon2 in a scripting language is a miserable experience. We’re talking quadratic performance penalties here. Several minutes of CPU time to calculate a hash that is far too weak to be acceptable in any context.
Consequently, not a single password manager I’ve evaluated that provides a browser extension uses a memory-hard algorithm for deriving encryption keys.
Update: I’ve been told Dashlane uses Argon2.

This Is Frustrating
When I write about cryptography, my goal is always to be clear, concise, and helpful. I want whoever reads my writing to, regardless of their level of expertise, walk away more comfortable with the subject matter.
At minimum, I want you to be able to intuit when you need to ask an expert for help, and have a slightly better understanding of how to word your questions to get the answer you need. In an ideal world, you’d even be able to spot the same kind of weaknesses I do in cryptography designs and implementations after reading enough of this blog.
I can’t do that with password-based cryptography. The use-cases and threat models are too varied to make a clear-cut recommendation, and it’s too complicated to parcel out in a way that doesn’t feel reductive or slightly contradictory. This leads to too many caveats or corner cases.
Passwords suck.
If you ask a password cracking expert and describe your use case, you’ll likely get an opinionated and definitive answer. But every time I’ve asked generally about this subject, without a specific use case in mind, I got an opinionated answer followed by a long chain of caveats and alternatives.
With that in mind, here’s a few vague guidelines that are up-to-date as of the end of 2022.

Recommendations for Password-Based Cryptography in 2023
Password Hashing
If you’re authenticating users in an online service (storing the hashes in a database), use any of the following algorithms:
- bcrypt with a cost factor appropriate to take about 100 milliseconds to compute on your server hardware (typically at least 12)
- scrypt with N = 32768, r = 8, p = 1 and a random salt at least 128 bits in length (256 preferred)
- Argon2id with a memory cost of 64 MiB, ops cost of 3, and parallelism of 1
If you’re forced to use PBKDF2 for whatever dumb reason, the parameters you want are at least:
- SHA-512 with 210,000 rounds (preferred)
- SHA-256 with 600,000 rounds
- SHA-1 (if you must) with 1,300,000 rounds
These numbers are based on constraining attackers to less than 10,000 hashes per second, per GPU.
I’m not currently recommending any algorithms deliberately designed for cache-hardness because they need further analysis from other cryptographers. (Bcrypt is minimally cache-hard, but that wasn’t a stated design goal.)
I didn’t evaluate the other PHC finalists nor other designs (Balloon hashing, Ball and Chain, etc.). Ask your cryptographer if those are appropriate instead.
Password-Based Key Derivation
If you’re deriving an encryption key from a password, use any of the following algorithms:
- scrypt with N = 1048576, r = 8, p = 1 and a random salt at least 128 bits in length (256 preferred)
- Argon2id with a memory cost of 1024 MiB, ops cost of 4, and parallelism of 1
If you’re forced to use PBKDF2 for whatever dumb reason, the parameters you want should target between 1 and 10 seconds on the defender’s hardware. If this is somehow slower than the numbers given for password hashing above, go with the password hashing benchmarks instead.
Here’s a dumb PHP script you can use to quickly find some target numbers.
<?php/* Dumb PBKDF2 benchmarking script by Soatok. 2022-12-29 */$salt = random_bytes(32);$password = 'correct horse battery staple';$c = '';$start = $end = microtime(true);foreach(['sha1', 'sha256', 'sha512'] as $alg) {foreach ([1 << 14,1 << 15,1 << 16,1 << 17,1 << 18,1 << 19,1 << 20,1200000,1 << 21,2500000,3000000,3500000,1 << 22,5000000,1 << 23,1 << 24,1 << 25,] as $n) { $start = microtime(true); $c ^= hash_pbkdf2($alg, $password, $salt, $n, 32, true); $end = microtime(true); $time = $end - $start; echo str_pad($n, 12, ' ', STR_PAD_LEFT), " iterations ({$alg}) -> \t", $time, PHP_EOL; if ($time > 5.5) { echo PHP_EOL; break; }}}
On my laptop, targeting 5.0 seconds means at least 4,000,000 rounds of PBKDF2 with SHA1, SHA256, or SHA512 (with SHA256 coming closer to 5,000,000).
If you’re aiming for less than 1,000 hashes per second per GPU, against an attacker armed with an RTX 4090:
- SHA-512 with 3,120,900 iterations (preferred)
- SHA256 with 8,900,000 iterations
- SHA-1 with 20,000,000 iterations
Sc00bz tells me that this generation of GPU has better performance/cost than previous generations (which had seen diminishing returns), but requires 1.5x the power, 1.78x the price, and 2x the physical space. Sc00bz refers to this as “1.5 GPUs”.
If you adjust for these factors, your final PBKDF2 target becomes:
- SHA-512 with 2,100,000 iterations (preferred)
- SHA-256 with 6,000,000 iterations
- SHA-1 with 13,000,000 iterations
Password Authenticated Key Exchanges
In a client-server model, where the server isn’t meant to see password-equivalent data, you want an augmented PAKE (or perhaps a doubly-augmented PAKE).
You’re overwhelmingly more likely to find OPAQUE support in the immediate future, due to the direction the IETF CFRG is moving today.
In a more peer-to-peer model, you want a balanced PAKE. CPace is the best game in town.
Don’t use SRP if you can help it.
If you can’t help it, make sure you use one of the groups defined in RFC 5054, rather than a generic Diffie-Hellman group. You’ll also want an expert to review your implementation to make sure your BigInt library isn’t leaking your users’ private exponents.
Also, feel free to deviate from SHA1 for calculating the private exponent from their username and password. SHA1 sucks. Nothing is stopping you from using a password KDF (or, at worst, SHA256) here, as long as you do so consistently.
(But as always, ask your cryptography expert first.)

TL;DR
Password-Based Cryptography is a mess.
If you’re not aware of the history of the field and the technical details that went into the various cryptographic algorithms that experts recommend today, it’s very easy to say something wrong that sounds correct to an untrained ear.
At the end of the day, the biggest risk you face with password-based cryptography is not using a suitable algorithm in the first place, rather than using a less optimal algorithm.
Experts have good reasons to hate PBDKF2 (slow for defenders, fast for attackers) and SRP (we have better options today, which also come with actual security proofs), but they certainly hate unsalted SHA1 and Triple-DES more.
My only real contribution to this topic is an effort to make it easier to talk about to non-experts by offering a new term for the superset of all of these password-based algorithms: Password-Based Cryptographic Functions.
Finally, the password cracking community is great. There are a lot of smart and friendly people involved, and they’re all working to make this problem easier to get right. If you’re not sure where to start, check out PasswordsCon.
 sticker")
https://soatok.blog/2022/12/29/what-we-do-in-the-etc-shadow-cryptography-with-passwords/
#cryptographicHashFunction #cryptographicProtocols #OPAQUE #passwordHashing #PBKDF2 #SecureRemotePasswordProtocol #SecurityGuidance

NIST opened public comments on SP 800-108 Rev. 1 (the NIST recommendations for Key Derivation Functions) last month. The main thing that’s changed from the original document published in 2009 is the inclusion of the Keccak-based KMAC alongside the incumbent algorithms.One of the recommendations of SP 800-108 is called “KDF in Counter Mode”. A related document, SP 800-56C, suggests using a specific algorithm called HKDF instead of the generic Counter Mode construction from SP 800-108–even though they both accomplish the same goal.
Isn’t standards compliance fun?
Interestingly, HKDF isn’t just an inconsistently NIST-recommended KDF, it’s also a common building block in a software developer’s toolkit which sees a lot of use in different protocols.
Unfortunately, the way HKDF is widely used is actually incorrect given its formal security definition. I’ll explain what I mean in a moment.
Art: Scruff
What is HKDF?
To first understand what HKDF is, you first need to know about HMAC.HMAC is a standard message authentication code (MAC) algorithm built with cryptographic hash functions (that’s the H). HMAC is specified in RFC 2104 (yes, it’s that old).
HKDF is a key-derivation function that uses HMAC under-the-hood. HKDF is commonly used in encryption tools (Signal, age). HKDF is specified in RFC 5869.
HKDF is used to derive a uniformly-random secret key, typically for use with symmetric cryptography algorithms. In any situation where a key might need to be derived, you might see HKDF being used. (Although, there may be better algorithms.)
Art: LvJ
How Developers Understand and Use HKDF
If you’re a software developer working with cryptography, you’ve probably seen an API in the crypto module for your programming language that looks like this, or maybe this.hash_hkdf( string $algo, string $key, int $length = 0, string $info = "", string $salt = ""): string
Software developers that work with cryptography will typically think of the HKDF parameters like so:
$algo— which hash function to use$key— the input key, from which multiple keys can be derived$length— how many bytes to derive$info— some arbitrary string used to bind a derived key to an intended context$salt— some additional randomness (optional)The most common use-case of HKDF is to implement key-splitting, where a single input key (the Initial Keying Material, or IKM) is used to derive two or more independent keys, so that you’re never using a single key for multiple algorithms.
See also:
[url=https://github.com/defuse/php-encryption]defuse/php-encryption[/url], a popular PHP encryption library that does exactly what I just described.At a super high level, the HKDF usage I’m describing looks like this:
class MyEncryptor {protected function splitKeys(CryptographyKey $key, string $salt): array { $encryptKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, 'encryption', $salt )); $authKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, 'message authentication', $salt )); return [$encryptKey, $authKey];}public function encryptString(string $plaintext, CryptographyKey $key): string{ $salt = random_bytes(32); [$encryptKey, $hmacKey] = $this->splitKeys($key, $salt); // ... encryption logic here ... return base64_encode($salt . $ciphertext . $mac);}public function decryptString(string $encrypted, CryptographyKey $key): string{ $decoded = base64_decode($encrypted); $salt = mb_substr($decoded, 0, 32, '8bit'); [$encryptKey, $hmacKey] = $this->splitKeys($key, $salt); // ... decryption logic here ... return $plaintext;}// ... other method here ...}
Unfortunately, anyone who ever does something like this just violated one of the core assumptions of the HKDF security definition and no longer gets to claim “KDF security” for their construction. Instead, your protocol merely gets to claim “PRF security”.
KDF? PRF? OMGWTFBBQ?
Let’s take a step back and look at some basic concepts.(If you want a more formal treatment, read this Stack Exchange answer.)
PRF: Pseudo-Random Functions
A pseudorandom function (PRF) is an efficient function that emulates a random oracle.“What the hell’s a random oracle?” you ask? Well, Thomas Pornin has the best explanation for random oracles:
A random oracle is described by the following model:
- There is a black box. In the box lives a gnome, with a big book and some dice.
- We can input some data into the box (an arbitrary sequence of bits).
- Given some input that he did not see beforehand, the gnome uses his dice to generate a new output, uniformly and randomly, in some conventional space (the space of oracle outputs). The gnome also writes down the input and the newly generated output in his book.
- If given an already seen input, the gnome uses his book to recover the output he returned the last time, and returns it again.
So a random oracle is like a kind of hash function, such that we know nothing about the output we could get for a given input message m. This is a useful tool for security proofs because they allow to express the attack effort in terms of number of invocations to the oracle.
The problem with random oracles is that it turns out to be very difficult to build a really “random” oracle. First, there is no proof that a random oracle can really exist without using a gnome. Then, we can look at what we have as candidates: hash functions. A secure hash function is meant to be resilient to collisions, preimages and second preimages. These properties do not imply that the function is a random oracle.
Thomas Pornin
Alternatively, Wikipedia has a more formal definition available to the academic-inclined.In practical terms, we can generate a strong PRF out of secure cryptographic hash functions by using a keyed construction; i.e. HMAC.
Thus, as long as your HMAC key is a secret, the output of HMAC can be generally treated as a PRF for all practical purposes. Your main security consideration (besides key management) is the collision risk if you truncate its output.
Art: LvJ
KDF: Key Derivation Functions
A key derivation function (KDF) is exactly what it says on the label: a cryptographic algorithm that derives one or more cryptographic keys from a secret input (which may be another cryptography key, a group element from a Diffie-Hellman key exchange, or a human-memorable password).Note that passwords should be used with a Password-Based Key Derivation Function, such as scrypt or Argon2id, not HKDF.
Despite what you may read online, KDFs do not need to be built upon cryptographic hash functions, specifically; but in practice, they often are.
A notable counter-example to this hash function assumption: CMAC in Counter Mode (from NIST SP 800-108) uses AES-CMAC, which is a variable-length input variant of CBC-MAC. CBC-MAC uses a block cipher, not a hash function.
Regardless of the construction, KDFs use a PRF under the hood, and the output of a KDF is supposed to be a uniformly random bit string.
Art: LvJ
PRF vs KDF Security Definitions
The security definition for a KDF has more relaxed requirements than PRFs: PRFs require the secret key be uniformly random. KDFs do not have this requirement.If you use a KDF with a non-uniformly random IKM, you probably need the KDF security definition.
If your IKM is already uniformly random (i.e. the “key separation” use case), you can get by with just a PRF security definition.
After all, the entire point of KDFs is to allow a congruent security level as you’d get from uniformly random secret keys, without also requiring them.
However, if you’re building a protocol with a security requirement satisfied by a KDF, but you actually implemented a PRF (i.e., not a KDF), this is a security vulnerability in your cryptographic design.
Art: LvJ
The HKDF Algorithm
HKDF is an HMAC-based KDF. Its algorithm consists of two distinct steps:
HKDF-Extractuses the Initial Keying Material (IKM) and Salt to produce a Pseudo-Random Key (PRK).HKDF-Expandactually derives the keys using PRK, theinfoparameter, and a counter (from0to255) for each hash function output needed to generate the desired output length.If you’d like to see an implementation of this algorithm,
defuse/php-encryptionprovides one (since it didn’t land in PHP until 7.1.0). Alternatively, there’s a Python implementation on Wikipedia that uses HMAC-SHA256.This detail about the two steps will matter a lot in just a moment.
Art: Swizz
How HKDF Salts Are Misused
The HKDF paper, written by Hugo Krawczyk, contains the following definition (page 7).
The paper goes on to discuss the requirements for authenticating the salt over the communication channel, lest the attacker have the ability to influence it.
A subtle detail of this definition is that the security definition says that A salt value
, not Multiple salt values.
Which means: You’re not supposed to use HKDF with a constant IKM, info label, etc. but vary the salt for multiple invocations. The salt must either be a fixed random value, or NULL.
The HKDF RFC makes this distinction even less clear when it argues for random salts.
We stress, however, that the use of salt adds significantly to the strength of HKDF, ensuring independence between different uses of the hash function, supporting “source-independent” extraction, and strengthening the analytical results that back the HKDF design.Random salt differs fundamentally from the initial keying material in two ways: it is non-secret and can be re-used. As such, salt values are available to many applications. For example, a pseudorandom number generator (PRNG) that continuously produces outputs by applying HKDF to renewable pools of entropy (e.g., sampled system events) can fix a salt value and use it for multiple applications of HKDF without having to protect the secrecy of the salt. In a different application domain, a key agreement protocol deriving cryptographic keys from a Diffie-Hellman exchange can derive a salt value from public nonces exchanged and authenticated between communicating parties as part of the key agreement (this is the approach taken in [IKEv2]).
RFC 5869, section 3.1
Okay, sure. Random salts are better than a NULL salt. And while this section alludes to “[fixing] a salt value” to “use it for multiple applications of HKDF without having to protect the secrecy of the salt”, it never explicitly states this requirement. Thus, the poor implementor is left to figure this out on their own.Thus, because it’s not using HKDF in accordance with its security definition, many implementations (such as the PHP encryption library we’ve been studying) do not get to claim that their construction has KDF security.
Instead, they only get to claim “Strong PRF” security, which you can get from just using HMAC.
What Purpose Do HKDF Salts Actually Serve?
Recall that the HKDF algorithm uses salts in the HDKF-Extract step. Salts in this context were intended for deriving keys from a Diffie-Hellman output, or a human-memorable password.In the case of [Elliptic Curve] Diffie-Hellman outputs, the result of the key exchange algorithm is a random group element, but not necessarily uniformly random bit string. There’s some structure to the output of these functions. This is why you always, at minimum, apply a cryptographic hash function to the output of [EC]DH before using it as a symmetric key.
HKDF uses salts as a mechanism to improve the quality of randomness when working with group elements and passwords.
Extending the nonce for a symmetric-key AEAD mode is a good idea, but using HKDF’s salt parameter specifically to accomplish this is a misuse of its intended function, and produces a weaker argument for your protocol’s security than would otherwise be possible.
How Should You Introduce Randomness into HKDF?
Just shove it in theinfoparameter.
Art: LvJ
It may seem weird, and defy intuition, but the correct way to introduce randomness into HKDF as most developers interact with the algorithm is to skip the salt parameter entirely (either fixing it to a specific value for domain-separation or leaving it NULL), and instead concatenate data into the
infoparameter.class BetterEncryptor extends MyEncryptor {protected function splitKeys(CryptographyKey $key, string $salt): array { $encryptKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, $salt . 'encryption', '' // intentionally empty )); $authKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, $salt . 'message authentication', '' // intentionally empty )); return [$encryptKey, $authKey];}}
Of course, you still have to watch out for canonicalization attacks if you’re feeding multi-part messages into the info tag.
Another advantage: This also lets you optimize your HKDF calls by caching the PRK from the
HKDF-Extractstep and reuse it for multiple invocations ofHKDF-Expandwith a distinctinfo. This allows you to reduce the number of hash function invocations fromto
(since each HMAC involves two hash function invocations).
Notably, this HKDF salt usage was one of the things that was changed in V3/V4 of PASETO.
Does This Distinction Really Matter?
If it matters, your cryptographer will tell you it matters–which probably means they have a security proof that assumes the KDF security definition for a very good reason, and you’re not allowed to violate that assumption.Otherwise, probably not. Strong PRF security is still pretty damn good for most threat models.
Art: LvJ
Closing Thoughts
If your takeaway was, “Wow, I feel stupid,” don’t, because you’re in good company.I’ve encountered several designs in my professional life that shoved the randomness into the
infoparameter, and it perplexed me because there was a perfectly good salt parameter right there. It turned out, I was wrong to believe that, for all of the subtle and previously poorly documented reasons discussed above. But now we both know, and we’re all better off for it.So don’t feel dumb for not knowing. I didn’t either, until this was pointed out to me by a very patient colleague.
(Art: LvJ)Also, someone should really get NIST to be consistent about whether you should use HKDF or “KDF in Counter Mode with HMAC” as a PRF, because SP 800-108’s new revision doesn’t concede this point at all (presumably a relic from the 2009 draft).
This concession was made separately in 2011 with SP 800-56C revision 1 (presumably in response to criticism from the 2010 HKDF paper), and the present inconsistency is somewhat vexing.
(On that note, does anyone actually use the NIST 800-108 KDFs instead of HKDF? If so, why? Please don’t say you need CMAC…)
Bonus Content
These questions were asked after this blog post initially went public, and I thought they were worth adding. If you ask a good question, it may end up being edited in at the end, too.
Art: LvJ
Why Does HKDF use the Salt as the HMAC key in the Extract Step? (via r/crypto)
Broadly speaking, when applying a PRF to two “keys”, you get to decide which one you treat as the “key” in the underlying API.HMAC’s API is HMACalg(key, message), but how HKDF uses it might as well be HMACalg(key1, key2).
The difference here seems almost arbitrary, but there’s a catch.
HKDF was designed for Diffie-Hellman outputs (before ECDH was the norm), which are generally able to be much larger than the block size of the underlying hash function. 2048-bit DH results fit in 256 bytes, which is 4 times the SHA256 block size.
If you have to make a decision, using the longer input (DH output) as the message is more intuitive for analysis than using it as the key, due to pre-hashing. I’ve discussed the counter-intuitive nature of HMAC’s pre-hashing behavior at length in this post, if you’re interested.
So with ECDH, it literally doesn’t matter which one was used (unless you have a weird mismatch in hash functions and ECC groups; i.e. NIST P-521 with SHA-224).
But before the era of ECDH, it was important to use the salt as the HMAC key in the extract step, since they were necessarily smaller than a DH group element.
Thus, HKDF chose HMACalg(salt, IKM) instead of HMACalg(IKM, salt) for the calculation of PRK in the HKDF-Extract step.
Neil Madden also adds that the reverse would create a chicken-egg situation, but I personally suspect that the pre-hashing would be more harmful to the security analysis than merely supplying a non-uniformly random bit string as an HMAC key in this specific context.
My reason for believing this is, when a salt isn’t supplied, it defaults to a string of
0x00bytes as long as the output size of the underlying hash function. If the uniform randomness of the salt mattered that much, this wouldn’t be a tolerable condition.https://soatok.blog/2021/11/17/understanding-hkdf/
#cryptographicHashFunction #cryptography #hashFunction #HMAC #KDF #keyDerivationFunction #securityDefinition #SecurityGuidance





Imagine you’re a software developer, and you need to authenticate users based on a username and password.
If you’re well-read on the industry standard best practices, you’ll probably elect to use something like bcrypt, scrypt, Argon2id, or PBKDF2. (If you thought to use something else, you’re almost certainly doing it wrong.)
Let’s say, due to technical constraints, that you’re forced to select PBKDF2 out of the above options, but you’re able to use a suitable hash function (i.e. SHA-256 or SHA-512, instead of SHA-1).
Every password is hashed with a unique 256-bit salt, generated from a secure random generator, and has an iteration count in excess of 80,000 (for SHA-512) or 100,000 (for SHA-256). So far, so good.

Let’s also say your users’ passwords are long, randomly-generated strings. This can mean either you’re building a community of password manager aficionados, or your users are actually software bots with API keys.
Every user’s password is, therefore, always a 256 character string of random hexadecimal characters.
Two sprints before your big launch, your boss calls you and says, “Due to arcane legal compliance reasons, we need to be able to detect duplicate passwords. It needs to be fast.”
You might might think, “That sounds like a hard problem to solve.”
Your boss insists, “The passwords are all too long and too high-entropy to reliably attacked, even when we’re using a fast hash, so we should be able to get by with a simple hash function for deduplication purposes.”
So you change your code to look like this:
<?phpuse ParagonIE\EasyDB\EasyDB;use MyApp\Security\PasswordHash;class Authentication { private EasyDB $db; public function __construct(EasyDB $db) { $this->db = $db; $this->pwhash = new PasswordHash('sha256'); } public function signUp(string $username, string $password) { // New: $hashed = hash('sha256', $password); if ($db->exists( "SELECT count(id) FROM users WHERE pw_dedupe = ?", $hashed )) { throw new Exception( "You cannot use the same username or password as another user." ); } // Original: if ($db->exists( "SELECT count(id) FROM users WHERE username = ?", $username )) { throw new Exception( "You cannot use the same username or password as another user." ); } $this->db->insert('users', [ 'username' => $username, 'pwhash' => $this->pwhash->hash($password), // Also new: 'pw_dedupe' => $hashed ]); } public function logIn(string $username, string $password): int { // This is unchanged: $user = $this->db->row("SELECT * FROM users WHERE username = ?", $username); if (empty($user)) { throw new Exception("Security Error: No user"); } if ($this->pwhash->verify($password, $user['pwhash'])) { throw new Exception("Security Error: Incorrect password"); } return (int) $user['id']; }}
Surely, this won’t completely undermine the security of the password hashing algorithm?

Three years later, a bored hacker discovers a read-only SQL injection vulnerability, and is immediately able to impersonate any user in your application.
What could have possibly gone wrong?
Cryptography Bugs Are Subtle
https://twitter.com/SwiftOnSecurity/status/832058185049579524
In order to understand what went wrong in our hypothetical scenario, you have to kinda know what’s under the hood in the monstrosity that our hypothetical developer slapped together.
PBKDF2
PBKDF2 stands for Password-Based Key Derivation Function #2. If you’re wondering where PBKDF1 went, I discussed its vulnerability in another blog post about the fun we can have with hash functions.
PBKDF2 is supposed to be instantiated with some kind of pseudo-random function, but it’s almost always HMAC with some hash function (SHA-1, SHA-256, and SHA-512 are common).
So let’s take a look at HMAC.
HMAC
HMAC is a Message Authentication Code algorithm based on Hash functions. Its definition looks like this:
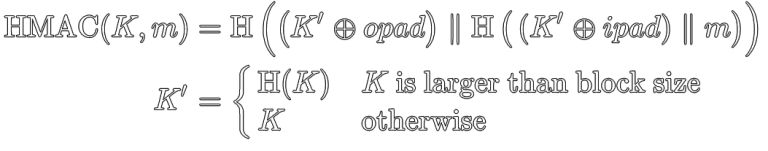
For the purposes of this discussion, we only care about the definition of K’.
If your key (K) is larger than the block size of the hash function, it gets pre-hashed with that hash function. If it’s less than or equal to the block size of the hash function, it doesn’t.
So, what is PBKDF2 doing with K?
How PBKDF2 Uses HMAC
The RFCs that define PBKDF2 aren’t super helpful here, but one needs only look at a reference implementation to see what’s happening.
// first iteration$last = $xorsum = hash_hmac($algorithm, $last, $password, true);// perform the other $count - 1 iterationsfor ($j = 1; $j < $count; $j++) {$xorsum ^= ($last = hash_hmac($algorithm, $last, $password, true));}$output .= $xorsum;
If you aren’t fluent in PHP, it’s using the previous round’s output as the message (m in the HMAC definition) and the password as the key (K).
Which means if your password is larger than the block size of the hash function used by HMAC (which is used by PBKDF2 under the hood), it will be pre-hashed.
The Dumbest Exploit Code
Okay, with all of that in mind, here’s how you can bypass the authentication of the above login script.
$httpClient->loginAs( $user['username'], hex2bin($user['pw_dedupe']));
Since K’ = H(K) when Length(K) > BlockSize(H), you can just take the pre-calculated hash of the user’s password and use that as the password (although not hex-encoded), and it will validate. (Demo.)

(Art by Khia.)
Above, when HMAC defined K’, it included a variant in its definition. Adding variants to hash function is a dumb way to introduce the risk of collisions. (See also: Trivial Collisions in IOTA’s Kerl hash function.)
Also, some PBKDF2 implementations that mishandle the pre-hashing of K, which can lead to denial-of-service attacks. Fun stuff, right?
Some Dumb Yet Effective Mitigations
Here are a few ways the hypothetical developer could have narrowly avoided this security risk:
- Use a different hash function for PBKDF2 and the deduplication check.
- e.g. PBKDF2-SHA256 and SHA512 would be impervious
- Always pre-hashing the password before passing it to PBKDF2.
- Our exploit attempt will effectively be double-hashed, and will not succeed.
- Use HMAC instead of a bare hash for the deduplication. With a hard-coded, constant key.
- Prefix the password with a distinct domain separation constant in each usage.
- Truncate the hash function, treating it as a Bloom filter.
- Some or all of the above.
- Push back on implementing this stupid feature to begin with.
Subtle problems often (but not always) call for subtle solutions.
Password Security Advice, Revisited
One dumb mitigation technique I didn’t include above is, “Using passwords shorter than the block size of the hash function.” The information security industry almost unanimously agrees that longer passwords are better than short ones (assuming both have the same distribution of possible characters at each position in the string, and are chosen randomly).
But here, we have a clear-cut example where having a longer password actually decreased security by allowing a trivial authentication bypass. Passwords with a length less than or equal to the block size of the hash function would not be vulnerable to the attack.
For reference, if you ever wanted to implement this control (assuming ASCII characters, where 1 character = 1 byte):
- 64-character passwords would be the upper limit for MD5, SHA-1, SHA-224, and SHA-256.
- 128-character passwords would be the upper limit for SHA-384 and SHA-512.
- (Since the above example used 256-character passwords, it always overflows.)
But really, one of the other mitigation techniques would be better. Limiting the input length is just a band-aid.
Another Non-Obvious Footgun
Converse to the block size of the hash function, the output size of the hash function also affects the security of PBKDF2, because each output is calculated sequentially. If you request more bytes out of a PBKDF2 function than the hash function outputs, it will have to work at least twice as hard.
This means that, while a legitimate user has to calculate the entire byte stream from PBKDF2, an attacker can just target the first N bytes (20 for SHA-1, 32 for SHA-256, 64 for SHA-512) of the raw hash output and attack that instead of doing all the work.
Is Cryptography Hard?
I’ve fielded a lot of questions in the past few weeks, and consequently overheard commentary from folks insisting that cryptography is a hard discipline and therefore only the smartest should study it. I disagree with that, but not for the reason that most will expect.
Many of the people reading this page will tell me, “This is such a dumb and obvious design flaw. Nobody would ship that code in production,” because they’re clever or informed enough to avoid disaster.
Yet, we still regularly hear about JWT alg=none vulnerabilities. And Johnny still still can’t encrypt. So cryptography surely can’t be easy.

Real-world cryptographic work is cognitively demanding. It becomes increasingly mathematically intensive the deeper you study, and nobody knows how to name things that non-cryptographers can understand. (Does anyone intuitively understand what a public key is outside of our field?)
In my opinion, cryptography is certainly challenging and widely misunderstood. There are a lot of subtle ways for secure building blocks to be stitched together insecurely. And today, it’s certainly a hard subject for most people to learn.
However, I don’t think its hardness is unavoidable.
Descending the Mohs Scale
There is a lot of gatekeeping in the information security community. (Maybe we should expect that to happen when people spend too many hours staring at firewall rules?)
“Don’t roll your own crypto” is something you hear a lot more often from software engineers and network security professionals than bona fide cryptographers.
Needless gatekeeping does the cryptographic community a severe disservice. I’m not the first to suggest that, either.
From what I’ve seen, far too many people feel discouraged from learning about cryptography, thinking they aren’t smart enough for it. It would seem A Mathematician’s Lament has an echo.
If it can be said that cryptography is hard today, then that has more to do with incomplete documentation and substandard education resources available for free online than some inherent mystical quality of our discipline that only the christened few can ever hope to master.
Cryptographers and security engineers that work in cryptography need more developers to play in our sandbox. We need more usability experts to discuss improvements to our designs and protocols to make them harder to misuse. We also need science communication experts and a legal strategy to stop idiotic politicians from trying to foolishly ban encryption.
So if you’re reading my blog, wondering, “Will I ever be smart enough to understand this crap?” the answer is probably “Yes!” It might not be easy, but with any luck, it’ll be easier than it was for the forerunners in our field.

(Art by Khia.)
I have one request, though: If you’re thinking of learning cryptography, please blog about your journey (even if you’re not a furry). You may end up filling in a pothole that would otherwise have tripped someone else up.
https://soatok.blog/2020/11/27/the-subtle-hazards-of-real-world-cryptography/
#computerSecurity #cryptographicHashFunction #cryptography #dumbExploit #HMAC #infosec #passwordHashing #PBKDF2 #SecurityGuidance

There are several different methods for securely hashing a password server-side for storage and future authentication. The most common one (a.k.a. the one that FIPS allows you to use, if compliance matters for you) is called PBKDF2. It stands for Password-Based Key Derivation Function #2.Why #2? It’s got nothing to do with pencils. There was, in fact, a PBKDF1! But PBKDF1 was fatally insecure in a way I find very interesting. This StackOverflow answer is a great explainer on the difference between the two.
Very Hand-Wavy Description of a Hash Function
Let’s defined a hash functionas any one-way transformation of some arbitrary-length string (
) to a fixed-length, deterministic, pseudo-random output.
Note: When in doubt, I err on the side of being easily understood by non-experts over pedantic precision. (Art by Swizz)
For example, this is a dumb hash function (uses SipHash-2-4 with a constant key):
function dumb_hash(string $arbitrary, bool $raw_binary = false): string{ $h = sodium_crypto_shorthash($arbitrary, 'SoatokDreamseekr'); if ($raw_binary) { return $h; } return sodium_bin2hex($h);}
You can see the output of this function with some sample inputs here.
Properties of Hash Functions
A hash function is considered secure if it has the following properties:
- Pre-image resistance. Given
- Second pre-image resistance. Given
, it should be difficult to find
such that
- Collision resistance. It should be difficult to find any arbitrary pair of messages (
) such that
That last property, collision resistance, is guaranteed up to the Birthday Bound of the hash function. For a hash function with a 256-bit output, you will expect to need on average
trial messages to find a collision.
If you’re confused about the difference between collision resistance and second pre-image resistance:
Collision resistance is about finding any two messages that produce the same hash, but you don’t care what the hash is as long as two distinct but known messages produce it.
On the other paw, second pre-image resistance is about finding a second message that produces a given hash.
Exploring PBKDF1’s Insecurity
If you recall, hash functions map an arbitrary-length string to a fixed-length string. If your input size is larger than your output size, collisions are inevitable (albeit computationally infeasible for hash functions such as SHA-256).But what if your input size is equal to your output size, because you’re taking the output of a hash function and feeding it directly back into the same hash function?
Then, as explained here, you get an depletion of the possible outputs with each successive iteration.
But what does that look like?
Without running the experiments on a given hash function, there are two possibilities that come to mind:
- Convergence. This is when
will, for two arbitrary messages and a sufficient number of iterations, converge on a single hash output.
- Cycles. This is when
for some integer
.
The most interesting result would be a quine, which is a cycle where
(that is to say,
).
The least interesting result would be for random inputs to converge into large cycles e.g. cycles of size
I calculated this lazily as the birthday bound of the birthday bound (so basically the 4th root, which foris
).
Update: According to this 1960 paper, the average time to cycle is
, and cycle length should be
, which means for a 256-bit hash you should expect a cycle after about
or about 128 bits, and the average cycle length will be about
. Thanks Riastradh for the corrections.
Conjecture: I would expect secure cryptographic hash functions in use today (e.g. SHA-256) to lean towards the least interesting output.
An Experiment Design
Since I don’t have an immense amount of cheap cloud computing at my disposal to run this experiments on a real hash function, I’m going to cheat a little and use my constant-key SipHash code from earlier in this post. In future work, cryptographers may find studying real hash functions (e.g. SHA-256) worthwhile.Given that SipHash is a keyed pseudo-random function with an output size of 64 bits, my dumb hash function can be treated as a 64-bit hash function.
This means that you should expect your first collision (with 50% probability) after only
trial hashes. This is cheap enough to try on a typical laptop.
Here’s a simple experiment for convergence:
- Generate two random strings
.
- Set
.
- Iterate
until
.
You can get the source code to run this trivial experiment here.
Clone the git repository, run
composer install, and thenphp bin/experiment.php. Note that this may need to run for a very long time before you get a result.If you get a result, you’ve found a convergence.
If the loop doesn’t terminate even after 2^64 iterations, you’ve definitely found a cycle. (Actually detecting a cycle and analyzing its length would require a lot of memory, and my simple PHP script isn’t suitable for this effort.)
“What do you mean I don’t have a petabyte of RAM at my disposal?”
What Does This Actually Tell Us?
The obvious lesson: Don’t design key derivation functions like PBKDF1.But beyond that, unless you can find a hash function that reliably converges or produces short cycles (
, for an n-bit hash function), not much. (This is just for fun, after all!)
Definitely fun to think about though! (Art by circuitslime)
If, however, a hash function is discovered to produce interesting results, this may indicate that the chosen hash function’s internal design is exploitable in some subtle ways that, upon further study, may lead to better cryptanalysis techniques. Especially if a hash quine is discovered.
(Header art by Khia)
https://soatok.blog/2020/05/05/putting-the-fun-in-hash-function/
#crypto #cryptography #hashFunction #SipHash

 = H(m_2)")


