Search
Items tagged with: cryptographicProtocols
If you follow me on Twitter, you probably already knew that I attended DEFCON 30 in Las Vegas.
If you were there in person, you probably also saw this particular nerd walking around:

The collar reads “Warning: PUNS” in a marquee.
In addition to being shamelessly furry and meeting a lot of really cool hackers (including several readers of this blog!), I attended several village talks (and at least one Sky Talk).
For some of these talks, I attended in fursuit. For others, I opted instead to bring my laptop and take notes. (Doing both things is ill-advised because it’s hard to type with paws, and the risk of laptop damage from excess sweat gives me pause, so it was one or the other.)
To be terse, my DEFCON experience was overwhelmingly positive. However, one talk at the Quantum Village had an extremely sus abstract (which was pointed out to me by Cendyne), so I decided to attend in person and see for myself.
Unfortunately, my intuition as a security engineer did not let me down, as we’ll explore below. But first, some background information.
What is DEFCON, Exactly?
(Feel free to skip this section if you already know.)
DEFCON is a hacking and security conference that takes place every year in Las Vegas, NV.
Unlike the stuffy Industry- and vendor-oriented events, DEFCON is more Community focused. Consequently, DEFCON has an inextricable counterculture element to it, and that makes it unique among security conferences.
(Some of the Security BSides events may also retain the same counterculture attitudes. However, that depends heavily on the attitudes of the local security/hacking scene. Give them a chance if you live near one, or consider starting your own.)
Put another way: DEFCON is to punk rock what USENIX is to classical. You’ll find good practitioners in both genres, and a surprising amount of overlap, but they can be appreciated independently too.
Which is why very few people balked at a group of furries running through Closing Ceremonies.
https://twitter.com/DCFurs/status/1558947697469448192
The weirdness and acceptance of DEFCON is a reflection of the diversity of the infosec community, and that’s a damn good thing.
In addition to DEFCON’s main track, there are a lot of so-called Villages that focus on different aspects of hacking, security, and the community.
For example, the Crypto & Privacy Village.

One of the many aspects of DEFCON is that you find yourself surrounded by people with deep expertise in many different areas (not just technological) who aren’t afraid to call you on any bullshit you spew. (Some of this fearlessness may be due to how much alcohol some people consume at the conference; I generally don’t drink alcohol, especially when fursuiting.)
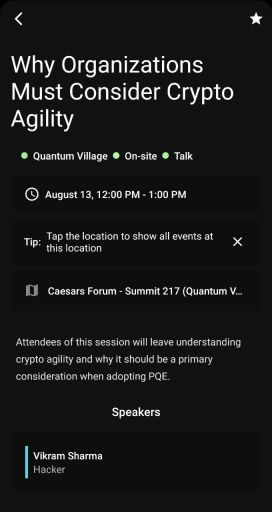
Vikram Sharma’s Talk at the Quantum Village at DEFCON 30
The M.C. of the Quantum Village introduced Vikram by saying, “You should know who he is,” and saying that he’s deeply involved in policy discussions with government agencies. He was also described as a TED speaker.
https://www.youtube.com/watch?v=SQB9zNWw9MA
I came to the talk intentionally unfamiliar with Vikram’s previous presentations, and with an open mind to the material he was going to share, so to avoid preconceived notions or unconscious bias as much as humanly possible.
The M.C.’s introduction primed me to expect a level of technical competence with cryptography and cryptanalysis on par with, or better than, a typical engineering manager that oversees cryptographers.
Vikram’s talk did not deliver on this built-up expectation.
Vikram Sharma’s Arguments
Vikram’s talk can be loosely distilled into a few important points:
- Cryptography-Relevant Quantum Computers are coming, and we don’t know when, but most experts believe within the next 30 years (at most).
- Although NIST has been working since 2015 on post-quantum cryptography, the advancements in cryptanalysis against Rainbow and SIKE highlight how nascent these algorithms are, and how brittle they may prove to be against mathematical advancements.
- In order to be ready to defend against Quantum Adversaries, we must adopt a mindset of “crypto agility” when engineering our applications.
- For enterprise customers, a Key Management Service that uses Quantum Key Distribution between endpoints in addition to post-quantum cryptography is likely necessary to hedge against advancements to post-quantum cryptanalysis.
The first two points are totally uncontroversial.
The third is interesting, and the fourth is a thinly-veiled sales pitch for Vikram’s company, QuintessenceLabs, rather than a serious technical argument.
Let’s explore the latter two points in more detail.

“Crypto Agility” From an Applied Cryptography Perspective
Protocols that utilize “crypto agility” are not new. SSL/TLS, SSH, and JWT all permit some degree of flexibility in the ciphersuite selection, rather than hard-coding the parameters.
For earlier versions of SSL/TLS, you could encrypt with RC4 with SHA1, and that was totally permitted. Stupid, but permitted. Nowadays, we use AES-GCM or ChaCha20-Poly1305 with TLS 1.3.
The story with SSH is similar, and there’s a lot of overlap in the user experience of configuring SSL/TLS for webservers and configuring OpenSSH. Even PGP supported different ciphers and modes. Crypto agility was the norm for many years.
JSON Web Tokens (JWT) is the perfect example of what happens when you take “crypto agility” too far:
- An attacker can change the
algheader’s value tononeto allow for trivial existential forgery. This surprises users. - An attacker can take an existing token that uses an asymmetric mode (
RS256,ES256, etc.), change thealgto a symmetric mode (i.e.HS256), then use the public key (or a hash of the public key) as a symmetric key, and the verifier would just blindly accept it.
When you maximize “crypto agility”, you introduce dangerous levels of in-band protocol negotiation.
Crypto Agility tends to become a security problem: When an attacker can entirely decide how the target system behaves, they can often bypass your security controls entirely.
Therefore, anyone who speaks in favor of crypto agility should be very careful about what, precisely, they’re advocating for.
Vikram’s talk wasn’t clear about these nuances. At the opening of the Q&A session, I asked the following question:
How do you balance your proposal for crypto agility with the risks of in-band protocol negotiation?
He declined to answer this question directly. Instead, he directed me to email his CTO, John Leiseboer, adding, “He would be better able to speak to that.”

So I returned to my DEFCON hotel room and sent an email to the email address that was displayed on Vikram’s slideshow.
Soatok’s First Email to QuintessenceLabs
This was mostly an attempt to be diplomatic so as to not scare them off from responding:
Hi,I attended your CEO’s talk at the Quantum Village at DEFCON 30. I was very interested in the subject, and Vikram’s delivery of the material was appropriate for the general audience. I did have one question, but he suggested that would be better answered by your CTO.
For a bit of background: I work in applied cryptography.
My question is, “How do you balance your proposal for crypto agility with the risks of in-band protocol negotiation?”
To add color to this question, consider the widely exploited standard, JSON Web Tokens. To change the cryptographic properties of a JWT, you only need to change the “alg” header. This is maximally agile.
Unfortunately, you can specify “none” as an algorithm. This surprises users: https://www.howmanydayssinceajwtalgnonevuln.com/
Additionally, an attacker can take a token signed with an asymmetric key (e.g. RSA), change the alg header to HMAC, and then use [a hash of] the asymmetric public key as if it were a symmetric HMAC key, and achieve trivial existential forgery.
The same concerns, I feel, will crop up when migrating to a hybrid post-quantum design. Cross-protocol interactions of the incorrect secret keys would, from by understanding of Vikram’s talk, be made possible if an attacker can mutate the metadata table.
There is a way out of this mess: Versioned Protocols. Using JWT as an example, a contrary proposal that can support cipher agility but only for ciphers (and constructions of ciphers) that cryptographers have approved is called PASETO. https://paseto.io
If a vulnerability in the current supported protocols (v3, v4) is discovered, the cryptographers behind PASETO will specify new modes (e.g. v5 and v6). Currently the only reason they’re considering any such migration is for hybrid post-quantum signatures (P384 + Dilithium, Ed25519 + Dilithium).
I think the general idea of crypto agility is the right direction for addressing the risk of cryptography relevant quantum computers, but I would caution against recreating the protocol foot-guns made possible by the wrong sort of agility.
Vikram suggested you would be able to speak more to how your designs take these threats into consideration. I’m very interested in this space and would love to learn more about how your designs work at a deeper level.
Thank you for your time,
Soatok
(Typos included in original email)
I didn’t hear back from them for several days, so I hunted down the CTO’s email address directly (thanks, old mailing list discussions!).
He quickly responded with this:
John Leiseboer’s First Response Email
Hi Soatok,My apologies for not responding sooner. I’ve been travelling and in meetings across three time zones. It’s been difficult to find time to absorb your questions and put together a response.
Please give me a few more days to find some time to get back to you.
Regards,
John
I want to pause here and make something very clear: My actual question is the most basic and obvious question any credible security engineer that works with cryptography would ask in response to Vikram’s presentation.

If you were to claim, “Everyone should use crypto agility,” and don’t qualify that statement with nuance or context, then a follow-up question about the risks of crypto agility is inevitable.
If this question somehow doesn’t come up, you’re in the wrong room of the wrong security engineers when you rehearse your pitch.
Why, then, would the speaker not be prepared for such a question? Isn’t he routinely offering similar talks to policy experts for government agencies?
Why, also, would his company’s CTO not be able to readily answer the question without needing additional time to “absorb” this question and put together a response?
It’s not like I asked them to provide a machine-verifiable, formal proof of correctness for their proposals.
I only asked the most basic Cryptography Protocol Design 101 question in response to their assertion that “crypto agility” is something that “companies” should adopt.
The proof, the proof, the proof is invalid!We don’t need no lemma–Proof by contradiction fail!
Fail, contradiction, fail!
With apologies to Rock Master Scott & The Dynamic Three
Was this company’s leadership blind-sided by the most basic question of the field of study they’re hoping to, at least in part, replace?
Did they fail to consider an attacker that alters the metadata associated with their encrypted data in order to convince the “agile” cryptosystems to misbehave?
I will update this post when I have an answer to these very interesting questions.
(Update) QuintessenceLabs Responds
This is one email, but I’m going to add my commentary between paragraph breaks.
Hello again Soatok,I’ve just read your blog where you criticised Vikram’s DEFCON talk. I was disappointed that you couldn’t wait for me to get back to you with the more detailed response that I promised to provide you last night.
Mea culpa. If I don’t press “publish” when the iron is hot, these posts stay in rough draft hell for 12-15 months, and I wanted to get my feedback (and the necessary context for said feedback) to the Quantum Village.
The short answer to your question, “How do you balance your proposal for crypto agility with the risks of in-band protocol negotiation?”, is simply that our proposal does not permit in-band negotiation. I suppose I could have provided you with that simple answer, but I expected that you’d want more than that. And I certainly wanted to provide you more. So, with apologies to Winston Churchill, if I had more time I would have written a shorter response.The problem with the term “crypto agility” is that it means different things to different people. In your case, you talk about the “crypto agility” of SSL/TLS, SSH and JWT. The problem, as you are aware, and point out in your email and blog, is that crypto agility, as implemented in these protocols, introduces security issues. At QuintessenceLabs we are well aware of the issues arising from the sort of crypto agility that provides too much flexibility to users (and attackers are a class of user as far as I’m concerned), and fails to account for imaginative use of the agile features.
Although I do not yet have access to Vikram’s slides, I will point out that the specific example used during the talk included encrypted credit card numbers and a separate metadata table that stored the algorithms used to encrypt said credit card numbers.
(He specifically spoke to upgrading from AES-128 to Kyber; which I thought was an odd proposition considering Kyber is a KEM not a symmetric cipher, but I dismissed that as misspeaking.)
Vikram’s metadata table proposal necessarily implies some kind of in-band negotiation, which is the bad type of crypto agility.
The following is taken from the introduction of an internal QuintessenceLabs Technical Note:“The term “cryptographic agility” is defined within QuintessenceLabs as a key management capability that permits the coding of software applications without the application code needing to specify or refer to specific cryptographic algorithms, key lengths, modes of operation, or similar cryptographic details. This capability enables applications to migrate between key types and cryptographic algorithms without a need to update the application software.
Specification of key types, strengths, modes, and cryptographic algorithms, etc. is the responsibility of a key management administrator. The key management platform delivers key material and meta data to applications in such a way that the cryptographic service or library used by the application can perform cryptographic operations in accordance with the attributes attached to the key material.”
This would have been very useful to include in the DEFCON talk. (It would have also been helpful if the speaker was prepared to answer such questions about the proposal!)
I generally think developers shouldn’t even need to care about the ciphers and algorithms being used; only that they’re secure, fast, and appropriate for their security goals. i.e. While AES-256-GCM might be okay for many use cases, it’s not how you should be storing users’ passwords.
In this regard, it sounds like the actual proposal is closer to NaCl/libsodium’s crypto_box() API, except the underlying library can tolerate algorithm upgrades (e.g. from X25519 + Xsalsa20poly1305 to something like X25519/Kyber768 + XChaCha20 + BLAKE2b-MAC). Which is totally reasonable.
This is very similar to what I did with my open source cryptography library, after all. It wraps libsodium, and if I decided to upgrade it to be post-quantum secure, I could do so without my users noticing (except maybe some bandwidth and performance differences).
The simplest way to tolerate such upgrades, by the by, is to use some sort of versioning scheme (which is the non-agile crypto design), which is what I’ve been proposing all along.
Some key points to note about our implementation:
- The application developer has absolutely no control over which algorithms, key lengths, modes of operation or other crypto-related attributes are used.
- The cryptographic key is actually a “managed object”. It is a protected object that encapsulates the key values and attributes that define how the key is to be used, including attributes such as cryptographic algorithm, key length, mode of operation, permitted uses (e.g. encrypt, decrypt, sign, signature verify, MAC, wrap, unwrap, etc.), links to related managed objects (e.g. a private key has an attribute that is it’s associated public key identifier), not-before and not-after time stamps, and maximum usage limits after which the key must be retired for use for protect operations.
- The cryptographic subsystem (whether that is an HSM, smart card, library, external service, …) presents a very simple API. Again from our internal Technical Note (was this in Vikram’s presentation?):
This is actually reasonable! Per Sophie Schmieg:
https://twitter.com/SchmiegSophie/status/1264567198091079681
“The application code is responsible for the business logic of the application. The application code makes no low level and direct cryptographic calls. Instead, it makes calls that abstract away the cryptographic details.An example of how this may work is as follows:
protected_data = protect(sensitive_data, policy);In this example the sensitive data is the data to be protected, the policy indicates what type of data, or type of protection is required, and the result returned is the protected data. More specifically, the policy could be a template name such as “CCN-Policy”, which might be used for protecting credit card numbers.”
I’m not sure I like this API (protect is way too vague), but the intent is much clearer than some vague notion of “crypto agility”.
The application is responsible for understanding the type of information it is working with. It needs to know whether it’s handling sensitive data or not. It needs to know whether sensitive data needs to be protected. It needs to know the classification of, or how to classify, the data. I think that’s reasonable, after all the application is implementing the business logic.
Why not simply encrypt everything by default and let developers specifically opt out for data classified as not sensitive?
Then if a developer adds a field down the road and somehow forgets to classify it, the database administrator only ever sees ciphertext.
So as the pseudo code above illustrates, the application passes the sensitive data and the classification (encoded in the ‘policy’ attribute) to the cryptographic subsystem to figure out what to do cryptographically.
If you can avoid developers having to even care about these details, while still getting the details right, that’s a win.
- The policy that defines the cryptographic attributes is separately managed. In the case of QuintessenceLabs’ products, this is the responsibility of a key management administrator, or a security officer, who has a cryptographic policy management role.
- The returned, protected data is an object, or structure that encapsulates not only the result of the cryptographic operation, but attributes that allow the inverse operation (“unprotect”) to be performed by the crypto subsystem.
This is actually not clownshoes. Thankfully.
- The policy can be changed at any time. This the agile part of the implementation. Today the policy says use AES-128-CBC, tomorrow is says use AES-256-GCM.
So, a couple of things about this specific example.
- AES-128-CBC is vulnerable to padding oracle attacks.
- If you support both AES-CBC and AES-GCM in the same code path, you can use the legacy CBC mode support to trigger a padding oracle attack to decrypt GCM ciphertexts.
Isn’t cryptography fun?

Adaptive attacks aside, cryptography migrations are way more challenging that your technical description implies. You’re going to have to do the following, in this specific order.
- Make sure your entire fleet can decrypt messages AES-GCM ciphertexts before any machine writes any data using AES-GCM.
- Only after step 1 is complete, you can upgrade your fleet to start writing records with AES-GCM.
- Re-encrypt all old records to use AES-GCM instead of AES-CBC.
- Turn off support for the legacy CBC mode.
If you attempt to move onto step 2 before step 1 is finished, you will find your network in a split-brain scenario where freshly-encrypted data cannot be read by some machines.
If you attempt to move onto step 3 before step 2 is finished, you will find some machines are still writing the legacy format.
If you attempt to move onto step 4 before step 3 is finished, you will lose access to some subset of old encrypted data.

It’s simply not possible to design a “crypto agile” application at any significant scale that totally avoids any window of downgrade susceptibility without also losing access to old encrypted data.
Until your entire network has reached step 4, you’re necessarily going to be vulnerable to in-band negotiation.
Also if you’re using the same key for multiple records (or the same wrapping key for multiple data keys), you’re going to read up on symmetric wear-out and the birthday paradox.
HKDF helps, but it has a specific way it needs to be used in security proofs.
Obviously as new algorithms are introduced, the crypto subsystem will need to be upgraded. But the application should not have to be changed.Please feel free to ask more questions. But please be patient. Right now I’m sitting at the check-in gate at Dulles Airport using a laptop with a battery rapidly running down. For the next 30 or so hours I’ll be flying back home to Australia. I’m always happy to receive questions. I would ask though that you have some respect for my time and give me a chance to catch my wind before you publish an article without allowing me the time to respond properly.
The technical details that were absent from the DEFCON talk I watched, which only cryptographers and security engineers will really care about, were essential and should have been included.
I still disagree about the properties of their proposed “crypto agility” in practice (especially at cloud scale, which seems to be where QuintessenceLabs’ CEO wants to operate), but at least this is a much more reasonable proposal.
(The remainder of this blog post remains unchanged from what was written before John’s reply was edited in.)
Against Quantum Key Distribution
While the response to my question about “crypto agility” was disappointing, their argument for Quantum Key Distribution is just weird.
Quantum Key Distribution (QKD) doesn’t scale well enough to protect consumers.
Suppose you’re accessing a brand new computer and want to login to your bank’s website to check your account balance. In this scenario, QKD is useless for you: You haven’t established a secure channel via quantum entanglement yet. You probably don’t even have the hardware or optic channel necessary to do so.
QuintessenceLabs doesn’t acknowledge this scaling issue explicitly in their Quantum Village slides. Instead, they pitch QKD as a solution for businesses (rather than users) that want to add a layer of quantum security to their Key Management Services (described vaguely as “interacting with HSMs”).
I’m not sure who exactly their intended audience is with this sales pitch: Are they trying to sell this to, or compete with, large cloud providers?

Either way, this isn’t the sort of thing that resonates well with most hackers (who are more aligned with protecting users than protecting companies), so DEFCON isn’t really the best venue for such a sales pitch.
To their credit, they don’t entirely handwave post-quantum cryptography as a solution to cryptography relevant quantum computers. Instead, they claim that QKD is an “optional” way to protect communications when post-quantum cryptography is broken. Vikram comes short of describing these algorithmic breaks as “inevitable” in his presentation.
Here’s the rub: QKD isn’t magic.
Just as the correct response to, “What’s your threat model?” isn’t, “Well why don’t you try to disprove Heisenberg? Checkmate atheists!” the solution to quantum computing isn’t to throw all of discrete mathematics out with the bathwater in favor of relying only on quantum entanglement.
Even if you assume that the physical properties being leveraged to secure QKD cannot be directly defeated, you still have to deal with side-channel attacks. Et cetera.
That’s not to say that QKD research isn’t valuable or interesting. But I would strongly caution anyone who’s considering deploying it in production to talk to cryptographers and other security experts first.

Art: Harubaki
Burning Trust at DEFCON 30
DEFCON isn’t at all a vendor expo like Black Hat USA where you send sales drones to hock blinkenboxen that claim to secure networks.
DEFCON is where serious researchers and eccentric geeks exchange 0days for cocktails and solve interesting technical challenges.
https://twitter.com/telechallenge/status/1558891761610723330
My point is: If you present bullshit at DEFCON, you will be called out on it.
When I sat down at the Quantum Village to watch Vikram’s presentation, I honestly wanted it to not be bullshit.
After all, a lot of talented hackers lack refinement in public speaking, especially with talk abstracts. Conversely, a lot of business people (i.e. the CEO of a company) might be so accustomed to writing abstracts for a different audience, even if they ultimately deliver a hacker-focused talk in the end.
Therefore, in my mind, it’s possible that the content of the talk would be surprisingly excellent. Unfortunately, I left disappointed.
I can’t help but wonder if Vikram’s company being one of the four sponsors for the nascent Quantum Village prevented the necessary bullshit filter from being utilized to screen his talk.
He, and his employees, might rightfully claim to be experts on quantum technology, but they certainly don’t understand cryptography as well as they like to believe.
The thought of a sponsor bypassing the bullshit filter certainly makes me a little distrustful of the Quantum Village going into DEFCON 31.
Recommendation for DEFCON 31 and Beyond
The Quantum Village should reach out to the Crypto & Privacy Village to help review any talks that involve cryptography, moving forward.
This will help in two ways:
- Cryptography and privacy experts will be involved in the process.
- Someone who doesn’t have a perverse incentive will likely be involved in the process, which makes it easier to tell a sponsor, “Hell no.”
A particularly motivated bullshit artist with sufficient capital might simply sponsor both villages, so it’s not 100% foolproof, but you can always count on weirdos in fursuits like me to be the last line of defense, should all else fail.
Update:
https://twitter.com/FiloSottile/status/1560165504312135680
I stand corrected. This attack vector won’t work. Thanks, Filippo!
Closing Thoughts
I was originally going to delay publishing this until QuintessenceLabs had a chance to respond to my question, or at least until all of the slide decks were published (so I could cite them carefully in my critique), but I honestly wanted to get my recommendation off my chest and in the hands of the Quantum Village organizers before I get distracted by the work that piled up while I was at DEFCON.
I might blog for free, but that doesn’t mean I don’t have a job to do, or bills to pay.
If you (or someone you work for) were sold on “crypto agility”, consider versioned protocols instead. And if you’re going to invest in custom hardware, take a page out of Nintendo’s book: simply burn fuses with each new protocol version to prevent downgrade attacks.
You probably don’t need quantum encryption to solve any of the problems you face in the immediate future.
https://soatok.blog/2022/08/18/burning-trust-at-the-quantum-village-at-defcon-30/
#cryptographicProtocols #cryptography #DEFCON #inBandNegotiation #JWT #postQuantumCryptography #QKD #QuantumEncryption #QuantumKeyDistribution #QuantumVillage #QuintessenceLabs #QuintessenceLabs #securityEngineering #VikramSharma

Sometimes my blog posts end up on social link-sharing websites with a technology focus, such as Lobste.rs or Hacker News.On a good day, this presents an opportunity to share one’s writing with a larger audience and, more importantly, solicit a wider variety of feedback from one’s peers.
However, sometimes you end up with feedback like this, or this:
Apparently my fursona is ugly, and therefore I’m supposed to respect some random person’s preferences and suppress my identity online.
I’m no stranger to gatekeeping in online communities, internet trolls, or bullying in general. This isn’t my first rodeo, and it won’t be my last.
These kinds of comments exist to send a message not just to me, but to anyone else who’s furry or overtly LGBTQIA+: You’re weird and therefore not welcome here.
Of course, the moderators rarely share their views.
https://twitter.com/pushcx/status/1281207233020379137
Because of their toxic nature, there is only one appropriate response to these kinds of comments: Loud and persistent spite.
So here’s some more art I’ve commissioned or been gifted of my fursona over the years that I haven’t yet worked into a blog post:
Art by kazetheblaze
Art by leeohfox
Art by Diffuse Moose
If you hate furries so much, you will be appalled to learn that factoids about my fursona species have landed in LibreSSL’s source code (decoded).
Never underestimate furries, because we make the Internets go.
I will never let these kind of comments discourage me from being open about my hobbies, interests, or personality. And neither should anyone else.
If you don’t like my blog posts because I’m a furry but still find the technical content interesting, know now and forever more that, when you try to push me or anyone else out for being different, I will only increase the fucking thing.
Header art created by @loviesophiee and inspired by floccinaucinihilipilification.
https://soatok.blog/2020/07/09/a-word-on-anti-furry-sentiments-in-the-tech-community/
#antiFurryBullying #cyberculture #furry #HackerNews #LobsteRs #Reddit




Ever since the famous “Open Sesame” line from One Thousand and One Nights, humanity was doomed to suffer from the scourge of passwords.
Even in a world where we use hardware tokens with asymmetric cryptography to obviate the need for passwords in modern authentication protocols, we’ll still need to include “something you know” for legal and political reasons.
In the United States, we have the Fifth Amendment to the US Constitution, which prevents anyone from being forced to testify against oneself. This sometimes includes revealing a password, so it is imperative that passwords remain a necessary component of some encryption technologies to prevent prosecutors from side-stepping one’s Fifth Amendment rights. (Other countries have different laws about passwords. I’m not a lawyer.)
If you’ve ever read anything from the EFF, you’re probably keenly aware of this, but the US government loves to side-step citizens’ privacy rights in a court of law. They do this not out of direct malice towards civil rights (generally), but rather because it makes their job easier. Incentives rule everything around me.
Thus, even in a passwordless future, anyone who truly cares about civil liberties will not want to dispense with them entirely. Furthermore, we’ll want these password-based technologies to pass the Mud Puddle test, so that we aren’t relying on large tech companies to protect us from government backdoors.
Given all this, most security professionals will agree that passwords suck. Not only are humans bad sources of randomness, but we’re awful at memorizing a sequence of characters or words for every application, website, or operating system that demands a password.
None of what I’ve written so far is the least bit novel or interesting. But here’s a spicy take:
The only thing that sucks worse than passwords is the messaging around password-based cryptographic functions.
Password-Based Cryptographic Functions
That isn’t a term of the art, by the way. I’m kind of coining it as a superset that includes both Password-Based Key Derivation Functions and Password Hashing Functions.
You might be wondering, “Aren’t those two the same thing?” No, they are not. I will explain in a moment.
The intersection of human-memorable secrets (passwords) and cryptographic protocols manifests in a lot of needless complexity and edge-cases that, in order to sufficiently explain anything conversationally, will require me to sound either drunk or like a blue deck player in Magic: The Gathering.

Art: CMYKat
To that end, what I’m calling Password-Based Cryptographic Functions (PBCFs) includes all of the following:
- Password-Hashing Functions
- Bcrypt
- Password-Based Key Derivation Functions
- Scrypt
- Argon2
- PBKDF2
- bscrypt
- Balanced Password Authenticated Key Exchanges
- CPace
- Augmented Password Authenticated Key Exchanges
- SRP
- AuCPace
- BS-SPEKE
- Doubly-Augmented Password Authenticated Key Exchanges
- OPAQUE
- Double BS-SPEKE
If you tried to approach categorization starting with simply “Key Derivation Functions”, you’d quickly run into a problem: What about HKDF? Or any of the NIST SP 800-108 KDFs for that matter?
If you tighten it to “Password-Based KDFs” or “Key-stretching functions”, that doesn’t include bcrypt. Bcrypt is a password hashing function, but it’s not suitable for deriving secret keys. I’ve discussed these nuances previously.
And then you have some password KDF and/or hashing algorithms that are memory-hard, some that are cache-hard.
And then some Password Authenticated Key Exchanges (PAKEs) are quantum-annoying, while others are not.

To make heads or tails of the different algorithms, their properties, and when and where you should use them, you’d either need to secure postdoc funding for cryptography research or spend a lot of time reading and watching passwords-focused conference talks.

(Selfie taken by Sc00bz (left) at DEFCON 30 in the Quantum Village.)
So let’s talk about these different algorithms, why they exist to begin with, and some of their technical details.

Why Does Any of This Matter?
The intersection of passwords and cryptography is one of the foundations of modern society, and one that most Internet users experience everywhere they go.
You’ll know you have succeeded in designing a cryptographic algorithm when the best way to attack it is to try every possible key. This is called an exhaustive search, or a brute-force attack, depending on the disposition of the author.
Remember earlier when I said passwords suck because humans are bad at creating or remembering strong, unique passwords for every website they visit?
Well, it turns out, that some passwords are extremely common. And even worse, people who choose common passwords tend to reuse them everywhere.
This presented a challenge to early web applications: In order to have authenticated users, you need to collect a password from the user and check it on subsequent visits. If you ever get hacked, then it’s likely that all of your users will be impacted on other websites they used the same passwords for.
Including their bank accounts.
So the challenge for any password-based scheme is simply stated: How can you safely authenticate users based on a secret they know?
Enter: Hashing
Storing a hash of a password is an obvious solution to this predicament. Early solutions involved using the user’s password as an encryption key, rather than building atop cryptographic hash functions.
However, it’s important not to call it “password encryption”.
The reason isn’t merely pedantic; it’s meant to prevent a disaster from repeating: Adobe famously encrypted passwords with Triple-DES instead of hashing them.
In early UNIX-based operating systems, your password hashes were stored in a file called /etc/passwd, along with other user account data. These days, your actual password hashes are kept in a second file, /etc/shadow, which is only readable by root.
Unfortunately, the tool used to create password hashes was called crypt, so the “encryption” lingo stuck.
When Hashing Isn’t Enough
Although encrypting passwords is bad, using a fast cryptographic hash function (e.g. SHA256 or BLAKE2) is also bad.
LinkedIn learned this lesson the hard way in 2012, when an attacker leaked 117 million users’ hashed passwords. It turns out, they used SHA1 as their password hashing function.
Hash functions are deterministic: If you feed them the same input, you will always get the same output.
When your password hashing strategy is simply “just use SHA1”, two users with the same password will have an identical password hash.
People are bad at creating, or remembering, unpredictable passwords.
When you combine these observations, there are some extremely obvious candidates (123456, password, etc.) to prioritize when guessing.
Additionally, you could precompute these hashes once and build a reverse index of the passwords that hash to a specific output. This is called a rainbow table.
Unlike most of symmetric cryptography, where the goal ends at forcing the attacker to perform an exhaustive brute-force search of every possible key, password-based cryptography has to go the extra mile to prevent weak secrets from being compromised; a very tall order for anyone to contend with.
Towards Modern Password Hashing
None of this was a surprise to security experts in 2012. There were a couple generally known best practices since I first learned programming in the 2000s:
- Salt your passwords (to mitigate rainbow tables)
- Use an iterated hashing scheme, rather than a fast hash (to make each step of an exhaustive search slower)
PBKDF2, the first widely used password hashing and key derivation function, did exactly that:
- PBKDF2 was designed to support randomly-generated per-user salts.
- It used HMAC in a loop to force attackers to spend extra CPU cycles per guess. If an attacker could guess 10 million passwords per second against SHA-256, then using 100,000 iterations of PBKDF2 slowed them down to less than 100 guesses per second (due to HMAC calling the hash function twice).
And that might sound like the end of the story (“PBKDF2 wins”), but the password cracking community is extremely clever, so it’s only just begun.
Parallel Attacks and GPUs
Since your CPU can only guess a few hashes per second, PBKDF2 is a thorny problem to contend with.
However, there’s an easy way for attackers to use commodity hardware to bypass this limitation: Graphics cards are specially designed to perform a lot of low-memory calculations in parallel.
If you can write your password cracking code to leverage the benefits of GPUs instead of CPUs, then PBKDF2 becomes easy potatoes.
The other secure password hashing algorithm in use at the time, bcrypt, had only a linear improvement over PBKDF2’s security against GPU attacks.
Memory-Hard Password Hashing Algorithms
In 2009, Colin Percival proposed scrypt to mitigate this risk. Scrypt (pronounced “ess crypt”) builds atop PBKDF2-SHA256 by hashing psuedorandom regions of memory with Salsa20/8 (hence the S in Scrypt) in a way that makes it difficult to precompute.
Scrypt hashes require large amounts of memory to compute (at least 16 megabytes, in the recommended minimum configuration, versus the few kilobytes of incumbent password hashes).
While GPUs (and FPGAs, and ASICs, and …) are great for cracking password hashes that use CPU-bounded algorithms, algorithms that access large amounts of memory are difficult to attack effectively.
It’s still possible for clever programmers to work around this memory/bandwidth limitation, but to do so, you must compute more operations, which makes it not worthwhile.
Cryptographers and the password-cracking community call this expensive time-memory trade-off memory hardness. In 2016, it was determined that scrypt is maximally memory-hard.
Password Hashing Competition
The Password Hashing Competition (PHC) was kicked off by JP Aumasson in 2012 to develop a new standard for password hashing and password-based key derivation.
In 2015, they selected Argon2 as its recommendation, with four finalists receiving special recognition (Catena, Lyra2, Makwa, and yescrypt–which is based on scrypt).
Cache-Hardness
In the years since the PHC concluded, the advances in password cracking techniques have not slowed down.
One of the PHC judges recently proposed a new algorithm called bscrypt which purports a property called “cache hard” rather than “memory hard”. The reasoning is that, for shorter run times, memory bandwidth and small CPU caches is a tighter bottleneck than overall memory requirements.
In fact, there’s an Argon2 variant (Argon2ds) which offers cache-hardness.
Two Hard Choices
So which of the two should you care about, as a defender?
If you’re validating password hashes in an online service, a cache-hard algorithm might make more sense. You’re incentivized to have shorter server-side run times to avoid DoS attacks, so the benefits of cache-hardness seem more impactful than memory-hardness.
If you’re deriving a sensitive cryptography key from a password and can afford to take several seconds of wall-clock time, a memory-hard algorithm is likely to be a better fit for your threat model.
(Or, like, run both a cache-hard and memory-hard algorithm and use a fast KDF, such as HKDF, to mix the two into your final cryptography key.)
Of course, the story doesn’t end here. Password Hashing and Password-Based Key Derivation continues to mature as the password cracking community discovers new attacks and engineers defenses against them.

A Strange Game; The Only Winning Move is to PAKE
Password hashing is a defense-in-depth against a system compromise that enables attackers to perform offline attacks against a cryptographic output to determine a user’s password.
However, for many applications, the bigger question is, “Why even play this game in the first place?”
Password-Authenticated Key Exchanges
A password authenticated key exchange (PAKE) algorithm is an interactive protocol to establish keys based on at least one party’s knowledge of a password.
PAKEs are what enable you to log into encrypted WiFi connections and encrypt your traffic. PAKEs prevent you from having to reveal the password (or a password-equivalent value, such as a password hash) to the other party.
Although there are a lot of proposed PAKE algorithms, the one that most people implemented was SRP (“Secure Remote Password”), which was intuitively a lot like Diffie-Hellman but also not Diffie-Hellman (since SRP used addition).
For a good teardown on SRP, Matthew Green’s blog is highly recommended.
There are a few real-world cryptography problems with using SRP:
- You need to use a special kind of prime number for your protocol. The standard Diffie-Hellman moduli are not suitable for SRP; you want a safe prime (i.e. a number of the form N = 2q + 1, where q is also prime).
- One of the steps in SRP, client-side, is to compute
A = g^a (mod N). Here,Ais a public value whileais a secret (usually the SHA1 hash of the username and pasword).
If your software implementation of modular exponentiation (a^x mod P) isn’t constant-time, you leaka, which is a password-equivalent value.
Additionally, it’s not possible to use SRP with elliptic curve groups. (Matthew Green’s post I linked above covers this in detail!)
Thus, SRP is generally considered to be deprecated by security experts, in favor of other PAKEs.
IETF, CFRG, PAKE Selection
As early as IETF 104, the Crypto Forum Research Group (CFRG) began exploring different PAKE algorithms to select for standardization.
One of the motivators for this work is that the WiFi alliance had shoehorned a new PAKE called Dragonfly into their WPA3, which turned out to be badly designed.
The CFRG’s candidate algorithms and reviews were publicly tracked on GitHub, if you’re curious.
TL;DR – They settled on recommending OPAQUE as an augmented PAKE and CPace as a balanced PAKE.
Sc00bz has done multiple talks at security conferences over the years to talk about PAKEs:
https://www.youtube.com/watch?v=28SM5ILpHEE
Quantum Annoyance
The PAKEs we’ve discussed involved a cyclic group (and the newer ones involved an elliptic curve group). The security of these schemes is dependent on the hardness of a discrete logarithm problem.
If a cryptography relevant quantum computer (CRQC) is developed, discrete logarithm problems will cease to be hard.
Some PAKEs fall apart the moment a discrete log is solvable. This is par for the course for Diffie-Hellman and elliptic curve cryptography.
Others require an attacker to solve a discrete log for every guess in an offline attack (after capturing a successful exchange). This makes them annoying for quantum attackers.
While they don’t provide absolute security like post-quantum cryptography, they do make attackers armed with a CRQC work harder.
OPAQUE isn’t quantum annoying. Simply observe all of the packets from making an online guess, solve the DLP offline, and you’re back to the realm of classical offline guessing.

The State of the Art
At this point, you may feel somewhat overwhelmed by all of this information. It’s very tempting to simplify all of this historical context and technical detail.
You might be telling yourself, “Okay, Scrypt, Argon2, CPace, OPAQUE. Got it. That’s all I need to remember. Everything else is questionable at best. Ask a cryptographer. I’m bailing out, yo!”
But the story gets worse on two fronts: Real-world operational requirements, and compliance.
Your Hands Are Tied, Now Swim
If you’re selling a product or service to the US government that uses cryptography, you need to first clear a bare minimum bar called FIPS 140.
FIPS 140 is opinionated about which algorithms you use. For password hashing and password-based key derivation, FIPS defers to NIST SP 800-209, which means you’re only permitted to use PBKDF2 in any FIPS modules (with a SHA2- family hash function). (Update: See below.)
So all of the information about memory-hard and cache-hard password hashing algorithms? This is useless for you if you ever try to sell to the US government.
An open question is whether Scrypt is FIPSable due to it building atop PBKDF2. To be blunt: I’m not sure. Ask a NIST Cryptographic Module Validation Program lab for their opinion.
Update (2022-01-07): A Brief Correction
Thanks to FreakLegion for pointing this out.
According to NIST SP 800-63B, memory-hard hash functions are recommended.
Examples of suitable key derivation functions include Password-based Key Derivation Function 2 (PBKDF2) [SP 800-132] and Balloon [BALLOON]. A memory-hard function SHOULD be used because it increases the cost of an attack.NIST SP 800-63B
Don’t use Balloon, though. It’s under-specified.
FreakLegion indicates in their Hacker News comment that scrypt and yescrypt are both acceptable.
End Update
In the realm of PAKEs, both CPace and OPAQUE are frameworks that can be used with multiple elliptic curve groups.
Both frameworks support NIST P-256, but CPace supports X25519 and OPAQUE supports Ristretto255; these are currently not FIPSable curves.
“I don’t care about FIPS. Argon2 all the things!”
JavaScript runtimes don’t provide a built-in Argon2 implementation. This poses several challenges.
- Do you care about iOS users? Lockdown mode prevents you from using WebAssembly, even in a browser extension.
- Trying to polyfill scrypt or Argon2 in a scripting language is a miserable experience. We’re talking quadratic performance penalties here. Several minutes of CPU time to calculate a hash that is far too weak to be acceptable in any context.
Consequently, not a single password manager I’ve evaluated that provides a browser extension uses a memory-hard algorithm for deriving encryption keys.
Update: I’ve been told Dashlane uses Argon2.

This Is Frustrating
When I write about cryptography, my goal is always to be clear, concise, and helpful. I want whoever reads my writing to, regardless of their level of expertise, walk away more comfortable with the subject matter.
At minimum, I want you to be able to intuit when you need to ask an expert for help, and have a slightly better understanding of how to word your questions to get the answer you need. In an ideal world, you’d even be able to spot the same kind of weaknesses I do in cryptography designs and implementations after reading enough of this blog.
I can’t do that with password-based cryptography. The use-cases and threat models are too varied to make a clear-cut recommendation, and it’s too complicated to parcel out in a way that doesn’t feel reductive or slightly contradictory. This leads to too many caveats or corner cases.
Passwords suck.
If you ask a password cracking expert and describe your use case, you’ll likely get an opinionated and definitive answer. But every time I’ve asked generally about this subject, without a specific use case in mind, I got an opinionated answer followed by a long chain of caveats and alternatives.
With that in mind, here’s a few vague guidelines that are up-to-date as of the end of 2022.

Recommendations for Password-Based Cryptography in 2023
Password Hashing
If you’re authenticating users in an online service (storing the hashes in a database), use any of the following algorithms:
- bcrypt with a cost factor appropriate to take about 100 milliseconds to compute on your server hardware (typically at least 12)
- scrypt with N = 32768, r = 8, p = 1 and a random salt at least 128 bits in length (256 preferred)
- Argon2id with a memory cost of 64 MiB, ops cost of 3, and parallelism of 1
If you’re forced to use PBKDF2 for whatever dumb reason, the parameters you want are at least:
- SHA-512 with 210,000 rounds (preferred)
- SHA-256 with 600,000 rounds
- SHA-1 (if you must) with 1,300,000 rounds
These numbers are based on constraining attackers to less than 10,000 hashes per second, per GPU.
I’m not currently recommending any algorithms deliberately designed for cache-hardness because they need further analysis from other cryptographers. (Bcrypt is minimally cache-hard, but that wasn’t a stated design goal.)
I didn’t evaluate the other PHC finalists nor other designs (Balloon hashing, Ball and Chain, etc.). Ask your cryptographer if those are appropriate instead.
Password-Based Key Derivation
If you’re deriving an encryption key from a password, use any of the following algorithms:
- scrypt with N = 1048576, r = 8, p = 1 and a random salt at least 128 bits in length (256 preferred)
- Argon2id with a memory cost of 1024 MiB, ops cost of 4, and parallelism of 1
If you’re forced to use PBKDF2 for whatever dumb reason, the parameters you want should target between 1 and 10 seconds on the defender’s hardware. If this is somehow slower than the numbers given for password hashing above, go with the password hashing benchmarks instead.
Here’s a dumb PHP script you can use to quickly find some target numbers.
<?php/* Dumb PBKDF2 benchmarking script by Soatok. 2022-12-29 */$salt = random_bytes(32);$password = 'correct horse battery staple';$c = '';$start = $end = microtime(true);foreach(['sha1', 'sha256', 'sha512'] as $alg) {foreach ([1 << 14,1 << 15,1 << 16,1 << 17,1 << 18,1 << 19,1 << 20,1200000,1 << 21,2500000,3000000,3500000,1 << 22,5000000,1 << 23,1 << 24,1 << 25,] as $n) { $start = microtime(true); $c ^= hash_pbkdf2($alg, $password, $salt, $n, 32, true); $end = microtime(true); $time = $end - $start; echo str_pad($n, 12, ' ', STR_PAD_LEFT), " iterations ({$alg}) -> \t", $time, PHP_EOL; if ($time > 5.5) { echo PHP_EOL; break; }}}
On my laptop, targeting 5.0 seconds means at least 4,000,000 rounds of PBKDF2 with SHA1, SHA256, or SHA512 (with SHA256 coming closer to 5,000,000).
If you’re aiming for less than 1,000 hashes per second per GPU, against an attacker armed with an RTX 4090:
- SHA-512 with 3,120,900 iterations (preferred)
- SHA256 with 8,900,000 iterations
- SHA-1 with 20,000,000 iterations
Sc00bz tells me that this generation of GPU has better performance/cost than previous generations (which had seen diminishing returns), but requires 1.5x the power, 1.78x the price, and 2x the physical space. Sc00bz refers to this as “1.5 GPUs”.
If you adjust for these factors, your final PBKDF2 target becomes:
- SHA-512 with 2,100,000 iterations (preferred)
- SHA-256 with 6,000,000 iterations
- SHA-1 with 13,000,000 iterations
Password Authenticated Key Exchanges
In a client-server model, where the server isn’t meant to see password-equivalent data, you want an augmented PAKE (or perhaps a doubly-augmented PAKE).
You’re overwhelmingly more likely to find OPAQUE support in the immediate future, due to the direction the IETF CFRG is moving today.
In a more peer-to-peer model, you want a balanced PAKE. CPace is the best game in town.
Don’t use SRP if you can help it.
If you can’t help it, make sure you use one of the groups defined in RFC 5054, rather than a generic Diffie-Hellman group. You’ll also want an expert to review your implementation to make sure your BigInt library isn’t leaking your users’ private exponents.
Also, feel free to deviate from SHA1 for calculating the private exponent from their username and password. SHA1 sucks. Nothing is stopping you from using a password KDF (or, at worst, SHA256) here, as long as you do so consistently.
(But as always, ask your cryptography expert first.)

TL;DR
Password-Based Cryptography is a mess.
If you’re not aware of the history of the field and the technical details that went into the various cryptographic algorithms that experts recommend today, it’s very easy to say something wrong that sounds correct to an untrained ear.
At the end of the day, the biggest risk you face with password-based cryptography is not using a suitable algorithm in the first place, rather than using a less optimal algorithm.
Experts have good reasons to hate PBDKF2 (slow for defenders, fast for attackers) and SRP (we have better options today, which also come with actual security proofs), but they certainly hate unsalted SHA1 and Triple-DES more.
My only real contribution to this topic is an effort to make it easier to talk about to non-experts by offering a new term for the superset of all of these password-based algorithms: Password-Based Cryptographic Functions.
Finally, the password cracking community is great. There are a lot of smart and friendly people involved, and they’re all working to make this problem easier to get right. If you’re not sure where to start, check out PasswordsCon.
 sticker")
https://soatok.blog/2022/12/29/what-we-do-in-the-etc-shadow-cryptography-with-passwords/
#cryptographicHashFunction #cryptographicProtocols #OPAQUE #passwordHashing #PBKDF2 #SecureRemotePasswordProtocol #SecurityGuidance

NIST opened public comments on SP 800-108 Rev. 1 (the NIST recommendations for Key Derivation Functions) last month. The main thing that’s changed from the original document published in 2009 is the inclusion of the Keccak-based KMAC alongside the incumbent algorithms.One of the recommendations of SP 800-108 is called “KDF in Counter Mode”. A related document, SP 800-56C, suggests using a specific algorithm called HKDF instead of the generic Counter Mode construction from SP 800-108–even though they both accomplish the same goal.
Isn’t standards compliance fun?
Interestingly, HKDF isn’t just an inconsistently NIST-recommended KDF, it’s also a common building block in a software developer’s toolkit which sees a lot of use in different protocols.
Unfortunately, the way HKDF is widely used is actually incorrect given its formal security definition. I’ll explain what I mean in a moment.
Art: Scruff
What is HKDF?
To first understand what HKDF is, you first need to know about HMAC.HMAC is a standard message authentication code (MAC) algorithm built with cryptographic hash functions (that’s the H). HMAC is specified in RFC 2104 (yes, it’s that old).
HKDF is a key-derivation function that uses HMAC under-the-hood. HKDF is commonly used in encryption tools (Signal, age). HKDF is specified in RFC 5869.
HKDF is used to derive a uniformly-random secret key, typically for use with symmetric cryptography algorithms. In any situation where a key might need to be derived, you might see HKDF being used. (Although, there may be better algorithms.)
Art: LvJ
How Developers Understand and Use HKDF
If you’re a software developer working with cryptography, you’ve probably seen an API in the crypto module for your programming language that looks like this, or maybe this.hash_hkdf( string $algo, string $key, int $length = 0, string $info = "", string $salt = ""): string
Software developers that work with cryptography will typically think of the HKDF parameters like so:
$algo— which hash function to use$key— the input key, from which multiple keys can be derived$length— how many bytes to derive$info— some arbitrary string used to bind a derived key to an intended context$salt— some additional randomness (optional)The most common use-case of HKDF is to implement key-splitting, where a single input key (the Initial Keying Material, or IKM) is used to derive two or more independent keys, so that you’re never using a single key for multiple algorithms.
See also:
[url=https://github.com/defuse/php-encryption]defuse/php-encryption[/url], a popular PHP encryption library that does exactly what I just described.At a super high level, the HKDF usage I’m describing looks like this:
class MyEncryptor {protected function splitKeys(CryptographyKey $key, string $salt): array { $encryptKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, 'encryption', $salt )); $authKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, 'message authentication', $salt )); return [$encryptKey, $authKey];}public function encryptString(string $plaintext, CryptographyKey $key): string{ $salt = random_bytes(32); [$encryptKey, $hmacKey] = $this->splitKeys($key, $salt); // ... encryption logic here ... return base64_encode($salt . $ciphertext . $mac);}public function decryptString(string $encrypted, CryptographyKey $key): string{ $decoded = base64_decode($encrypted); $salt = mb_substr($decoded, 0, 32, '8bit'); [$encryptKey, $hmacKey] = $this->splitKeys($key, $salt); // ... decryption logic here ... return $plaintext;}// ... other method here ...}
Unfortunately, anyone who ever does something like this just violated one of the core assumptions of the HKDF security definition and no longer gets to claim “KDF security” for their construction. Instead, your protocol merely gets to claim “PRF security”.
KDF? PRF? OMGWTFBBQ?
Let’s take a step back and look at some basic concepts.(If you want a more formal treatment, read this Stack Exchange answer.)
PRF: Pseudo-Random Functions
A pseudorandom function (PRF) is an efficient function that emulates a random oracle.“What the hell’s a random oracle?” you ask? Well, Thomas Pornin has the best explanation for random oracles:
A random oracle is described by the following model:
- There is a black box. In the box lives a gnome, with a big book and some dice.
- We can input some data into the box (an arbitrary sequence of bits).
- Given some input that he did not see beforehand, the gnome uses his dice to generate a new output, uniformly and randomly, in some conventional space (the space of oracle outputs). The gnome also writes down the input and the newly generated output in his book.
- If given an already seen input, the gnome uses his book to recover the output he returned the last time, and returns it again.
So a random oracle is like a kind of hash function, such that we know nothing about the output we could get for a given input message m. This is a useful tool for security proofs because they allow to express the attack effort in terms of number of invocations to the oracle.
The problem with random oracles is that it turns out to be very difficult to build a really “random” oracle. First, there is no proof that a random oracle can really exist without using a gnome. Then, we can look at what we have as candidates: hash functions. A secure hash function is meant to be resilient to collisions, preimages and second preimages. These properties do not imply that the function is a random oracle.
Thomas Pornin
Alternatively, Wikipedia has a more formal definition available to the academic-inclined.In practical terms, we can generate a strong PRF out of secure cryptographic hash functions by using a keyed construction; i.e. HMAC.
Thus, as long as your HMAC key is a secret, the output of HMAC can be generally treated as a PRF for all practical purposes. Your main security consideration (besides key management) is the collision risk if you truncate its output.
Art: LvJ
KDF: Key Derivation Functions
A key derivation function (KDF) is exactly what it says on the label: a cryptographic algorithm that derives one or more cryptographic keys from a secret input (which may be another cryptography key, a group element from a Diffie-Hellman key exchange, or a human-memorable password).Note that passwords should be used with a Password-Based Key Derivation Function, such as scrypt or Argon2id, not HKDF.
Despite what you may read online, KDFs do not need to be built upon cryptographic hash functions, specifically; but in practice, they often are.
A notable counter-example to this hash function assumption: CMAC in Counter Mode (from NIST SP 800-108) uses AES-CMAC, which is a variable-length input variant of CBC-MAC. CBC-MAC uses a block cipher, not a hash function.
Regardless of the construction, KDFs use a PRF under the hood, and the output of a KDF is supposed to be a uniformly random bit string.
Art: LvJ
PRF vs KDF Security Definitions
The security definition for a KDF has more relaxed requirements than PRFs: PRFs require the secret key be uniformly random. KDFs do not have this requirement.If you use a KDF with a non-uniformly random IKM, you probably need the KDF security definition.
If your IKM is already uniformly random (i.e. the “key separation” use case), you can get by with just a PRF security definition.
After all, the entire point of KDFs is to allow a congruent security level as you’d get from uniformly random secret keys, without also requiring them.
However, if you’re building a protocol with a security requirement satisfied by a KDF, but you actually implemented a PRF (i.e., not a KDF), this is a security vulnerability in your cryptographic design.
Art: LvJ
The HKDF Algorithm
HKDF is an HMAC-based KDF. Its algorithm consists of two distinct steps:
HKDF-Extractuses the Initial Keying Material (IKM) and Salt to produce a Pseudo-Random Key (PRK).HKDF-Expandactually derives the keys using PRK, theinfoparameter, and a counter (from0to255) for each hash function output needed to generate the desired output length.If you’d like to see an implementation of this algorithm,
defuse/php-encryptionprovides one (since it didn’t land in PHP until 7.1.0). Alternatively, there’s a Python implementation on Wikipedia that uses HMAC-SHA256.This detail about the two steps will matter a lot in just a moment.
Art: Swizz
How HKDF Salts Are Misused
The HKDF paper, written by Hugo Krawczyk, contains the following definition (page 7).
The paper goes on to discuss the requirements for authenticating the salt over the communication channel, lest the attacker have the ability to influence it.
A subtle detail of this definition is that the security definition says that A salt value
, not Multiple salt values.
Which means: You’re not supposed to use HKDF with a constant IKM, info label, etc. but vary the salt for multiple invocations. The salt must either be a fixed random value, or NULL.
The HKDF RFC makes this distinction even less clear when it argues for random salts.
We stress, however, that the use of salt adds significantly to the strength of HKDF, ensuring independence between different uses of the hash function, supporting “source-independent” extraction, and strengthening the analytical results that back the HKDF design.Random salt differs fundamentally from the initial keying material in two ways: it is non-secret and can be re-used. As such, salt values are available to many applications. For example, a pseudorandom number generator (PRNG) that continuously produces outputs by applying HKDF to renewable pools of entropy (e.g., sampled system events) can fix a salt value and use it for multiple applications of HKDF without having to protect the secrecy of the salt. In a different application domain, a key agreement protocol deriving cryptographic keys from a Diffie-Hellman exchange can derive a salt value from public nonces exchanged and authenticated between communicating parties as part of the key agreement (this is the approach taken in [IKEv2]).
RFC 5869, section 3.1
Okay, sure. Random salts are better than a NULL salt. And while this section alludes to “[fixing] a salt value” to “use it for multiple applications of HKDF without having to protect the secrecy of the salt”, it never explicitly states this requirement. Thus, the poor implementor is left to figure this out on their own.Thus, because it’s not using HKDF in accordance with its security definition, many implementations (such as the PHP encryption library we’ve been studying) do not get to claim that their construction has KDF security.
Instead, they only get to claim “Strong PRF” security, which you can get from just using HMAC.
What Purpose Do HKDF Salts Actually Serve?
Recall that the HKDF algorithm uses salts in the HDKF-Extract step. Salts in this context were intended for deriving keys from a Diffie-Hellman output, or a human-memorable password.In the case of [Elliptic Curve] Diffie-Hellman outputs, the result of the key exchange algorithm is a random group element, but not necessarily uniformly random bit string. There’s some structure to the output of these functions. This is why you always, at minimum, apply a cryptographic hash function to the output of [EC]DH before using it as a symmetric key.
HKDF uses salts as a mechanism to improve the quality of randomness when working with group elements and passwords.
Extending the nonce for a symmetric-key AEAD mode is a good idea, but using HKDF’s salt parameter specifically to accomplish this is a misuse of its intended function, and produces a weaker argument for your protocol’s security than would otherwise be possible.
How Should You Introduce Randomness into HKDF?
Just shove it in theinfoparameter.
Art: LvJ
It may seem weird, and defy intuition, but the correct way to introduce randomness into HKDF as most developers interact with the algorithm is to skip the salt parameter entirely (either fixing it to a specific value for domain-separation or leaving it NULL), and instead concatenate data into the
infoparameter.class BetterEncryptor extends MyEncryptor {protected function splitKeys(CryptographyKey $key, string $salt): array { $encryptKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, $salt . 'encryption', '' // intentionally empty )); $authKey = new CryptographyKey(hash_hkdf( 'sha256', $key->getRawBytes(), 32, $salt . 'message authentication', '' // intentionally empty )); return [$encryptKey, $authKey];}}
Of course, you still have to watch out for canonicalization attacks if you’re feeding multi-part messages into the info tag.
Another advantage: This also lets you optimize your HKDF calls by caching the PRK from the
HKDF-Extractstep and reuse it for multiple invocations ofHKDF-Expandwith a distinctinfo. This allows you to reduce the number of hash function invocations fromto
(since each HMAC involves two hash function invocations).
Notably, this HKDF salt usage was one of the things that was changed in V3/V4 of PASETO.
Does This Distinction Really Matter?
If it matters, your cryptographer will tell you it matters–which probably means they have a security proof that assumes the KDF security definition for a very good reason, and you’re not allowed to violate that assumption.Otherwise, probably not. Strong PRF security is still pretty damn good for most threat models.
Art: LvJ
Closing Thoughts
If your takeaway was, “Wow, I feel stupid,” don’t, because you’re in good company.I’ve encountered several designs in my professional life that shoved the randomness into the
infoparameter, and it perplexed me because there was a perfectly good salt parameter right there. It turned out, I was wrong to believe that, for all of the subtle and previously poorly documented reasons discussed above. But now we both know, and we’re all better off for it.So don’t feel dumb for not knowing. I didn’t either, until this was pointed out to me by a very patient colleague.
(Art: LvJ)Also, someone should really get NIST to be consistent about whether you should use HKDF or “KDF in Counter Mode with HMAC” as a PRF, because SP 800-108’s new revision doesn’t concede this point at all (presumably a relic from the 2009 draft).
This concession was made separately in 2011 with SP 800-56C revision 1 (presumably in response to criticism from the 2010 HKDF paper), and the present inconsistency is somewhat vexing.
(On that note, does anyone actually use the NIST 800-108 KDFs instead of HKDF? If so, why? Please don’t say you need CMAC…)
Bonus Content
These questions were asked after this blog post initially went public, and I thought they were worth adding. If you ask a good question, it may end up being edited in at the end, too.
Art: LvJ
Why Does HKDF use the Salt as the HMAC key in the Extract Step? (via r/crypto)
Broadly speaking, when applying a PRF to two “keys”, you get to decide which one you treat as the “key” in the underlying API.HMAC’s API is HMACalg(key, message), but how HKDF uses it might as well be HMACalg(key1, key2).
The difference here seems almost arbitrary, but there’s a catch.
HKDF was designed for Diffie-Hellman outputs (before ECDH was the norm), which are generally able to be much larger than the block size of the underlying hash function. 2048-bit DH results fit in 256 bytes, which is 4 times the SHA256 block size.
If you have to make a decision, using the longer input (DH output) as the message is more intuitive for analysis than using it as the key, due to pre-hashing. I’ve discussed the counter-intuitive nature of HMAC’s pre-hashing behavior at length in this post, if you’re interested.
So with ECDH, it literally doesn’t matter which one was used (unless you have a weird mismatch in hash functions and ECC groups; i.e. NIST P-521 with SHA-224).
But before the era of ECDH, it was important to use the salt as the HMAC key in the extract step, since they were necessarily smaller than a DH group element.
Thus, HKDF chose HMACalg(salt, IKM) instead of HMACalg(IKM, salt) for the calculation of PRK in the HKDF-Extract step.
Neil Madden also adds that the reverse would create a chicken-egg situation, but I personally suspect that the pre-hashing would be more harmful to the security analysis than merely supplying a non-uniformly random bit string as an HMAC key in this specific context.
My reason for believing this is, when a salt isn’t supplied, it defaults to a string of
0x00bytes as long as the output size of the underlying hash function. If the uniform randomness of the salt mattered that much, this wouldn’t be a tolerable condition.https://soatok.blog/2021/11/17/understanding-hkdf/
#cryptographicHashFunction #cryptography #hashFunction #HMAC #KDF #keyDerivationFunction #securityDefinition #SecurityGuidance



